Introducing Sep - Possibly the World's Fastest .NET CSV Parser
Since late 2021 and the initial .NET releases with support for Generic
Math and in
particular
ISpanParsable<T>
and ISpanFormattable
, I have
been working on a new CSV library for .NET. The library is called
Sep, short for separator. In this blog post I
will introduce Sep v0.1.0 with a copy of
README.md file from GitHub
(slightly edited) and then follow up with a deep dive into the SIMD assembly
that is part of what makes Sep fast. And a look at CPU usage based on profiling
data, so please be sure to stick around or just jump to SepReader Deep
Dive.
The README-file will be updated as the library (hopefulyl) matures, so please be sure to check that out on GitHub for the latest information or follow below.
![]()
![]()

Sep (v0.1.0)
Modern, minimal, fast, zero allocation, reading and writing of separated values
(csv, tsv etc.). Cross-platform, trimmable and AOT/NativeAOT compatible.
Featuring an opinionated API design and pragmatic implementation targetted at
machine learning use cases.
- 🌃 Modern - utilizes features such as
Span<T>, Generic Math (ISpanParsable<T>/ISpanFormattable),ref struct,ArrayPool<T>and similar from .NET 7+ and C# 11+ for a modern and highly efficient implementation. - 🔎 Minimal - a succinct yet expressive API with few options and no hidden changes to input or output. What you read/write is what you get. This means there is no “automatic” escaping/unescaping of quotes, for example.
- 🚀 Fast - blazing fast with both architecture specific and cross-platform SIMD vectorized parsing. Uses csFastFloat for fast parsing of floating points. Reads or writes one row at a time efficiently with detailed benchmarks to prove it.
- 🗑️ Zero allocation - intelligent and efficient memory management allowing for zero allocations after warmup incl. supporting use cases of reading or writing arrays of values (e.g. features) easily without repeated allocations.
- 🌐 Cross-platform - works on any platform, any architecture supported by .NET. 100% managed and written in beautiful modern C#.
- ✂️ Trimmable and AOT/NativeAOT compatible - no problematic reflection or dynamic code generation. Hence, fully trimmable and Ahead-of-Time compatible. With a simple console tester program executable possible in just a few MBs. 💾
- 🗣️ Opinionated and pragmatic - conforms to the essentials of RFC-4180, but takes an opinionated and pragmatic approach towards this especially with regards to quoting and line ends.
Example
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
var text = """
A;B;C;D;E;F
Sep;🚀;1;1.2;0.1;0.5
CSV;✅;2;2.2;0.2;1.5
""";
using var reader = Sep.Reader().FromText(text); // Infers separator 'Sep' from header
using var writer = reader.Spec.Writer().ToText(); // Writer defined from reader 'Spec'
// Use .FromFile(...)/ToFile(...) for files
var idx = reader.Header.IndexOf("B");
var nms = new[] { "E", "F" };
foreach (var readRow in reader) // Read one row at a time
{
var a = readRow["A"].Span; // Column as ReadOnlySpan<char>
var b = readRow[idx].ToString(); // Column to string (might be pooled)
var c = readRow["C"].Parse<int>(); // Parse any T : ISpanParsable<T>
var d = readRow["D"].Parse<float>(); // Parse float/double fast via csFastFloat
var s = readRow[nms].Parse<double>(); // Parse multiple columns as Span<T>
// - Sep handles array allocation and reuse
foreach (ref var v in s) { v *= 10; }
using var writeRow = writer.NewRow(); // Start new row. Row written on Dispose.
writeRow["A"].Set(a); // Set by ReadOnlySpan<char>
writeRow["B"].Set(b); // Set by string
writeRow["C"].Set($"{c * 2}"); // Set via InterpolatedStringHandler, no allocs
writeRow["D"].Format(d / 2); // Format any T : ISpanFormattable
writeRow[nms].Format(s); // Format multiple columns directly
// Columns are added on first access as ordered, header written when first row written
}
var expected = """
A;B;C;D;E;F
Sep;🚀;2;0.6;1;5
CSV;✅;4;1.1;2;15
""";
Assert.AreEqual(expected, writer.ToString());
// Above example code is for demonstration purposes only.
// Short names and repeated constants are only for demonstration.
Naming and Terminology
Sep uses naming and terminology that is not based on RFC-4180, but is more
tailored to usage in machine learning or similar. Additionally, Sep takes a
pragmatic approach towards names by using short names and abbreviations where it
makes sense and there should be no ambiguity given the context. That is, using
Sep for Separator and Col for Column to keep code succinct.
| Term | Description |
|---|---|
Sep |
Short for separator, also called delimiter. E.g. comma (,) is the separator for the separated values in a csv-file. |
Header |
Optional first row defining names of columns. |
Row |
A row is a collection of col(umn)s, which may span multiple lines. Also called record. |
Col |
Short for column, also called field. |
Line |
Horizontal set of characters until a line ending; \r\n, \r, \n. |
Index |
0-based that is RowIndex will be 0 for first row (or the header if present). |
Number |
1-based that is LineNumber will be 1 for the first line (as in notepad). Given a row may span multiple lines a row can have a start line number and an end line number. |
Application Programming Interface (API)
Besides being the succinct name of the library, Sep is both the main entry
point to using the library and the container for a validated separator. That is,
Sep is basically defined as:
1
public readonly record struct Sep(char Separator);
The separator char is validated upon construction and is guaranteed to be
within a limited range and not being a char like " (quote) or similar. This
can be seen in Sep.cs. The separator is constrained
also for internal optimizations, so you cannot use any char as a separator.
⚠ Note that all types are within the namespace nietras.SeparatedValues and not
Sep since it is problematic to have a type and a namespace with the same name.
To get started you can use Sep as the static entry point to building either a
reader or writer. That is, for SepReader:
1
using var reader = Sep.Reader().FromFile("titanic.csv");
where .Reader() is a convenience method corresponding to:
1
using var reader = Sep.Auto.Reader().FromFile("titanic.csv");
where Sep? Auto => null; is a static property that returns null for a
nullable Sep to signify that the separator should be inferred from the first
row, which might be a header. If the first row does not contain any of the by
default supported separators or there are no rows, the default separator will be
used.
⚠ Note Sep uses ; as the default separator, since this is what was used in an
internal proprietary library which Sep was built to replace. This is also to
avoid issues with comma , being used as a decimal separator in some locales.
Without having to resort to quoting.
If you want to specify the separator you can write:
1
using var reader = Sep.New(',').Reader().FromFile("titanic.csv");
or
1
2
var sep = new Sep(',');
using var reader = sep.Reader().FromFile("titanic.csv");
Similarly, for SepWriter:
1
using var writer = Sep.Writer().ToFile("titanic.csv");
or
1
using var writer = Sep.New(',').Writer().ToFile("titanic.csv");
where you have to specify a valid separator, since it cannot be inferred. To
fascillitate easy flow of the separator and CultureInfo both SepReader and
SepWriter expose a Spec property of type SepSpec that simply defines those
two. This means you can write:
1
2
using var reader = Sep.Reader().FromFile("titanic.csv");
using var writer = reader.Spec.Writer().ToFile("titanic-survivors.csv");
where the writer then will use the separator inferred by the reader, for
example.
API Pattern
In general, both reading and writing follow a similar pattern:
1
2
Sep/Spec => SepReaderOptions => SepReader => Row => Col(s) => Span/ToString/Parse
Sep/Spec => SepWriterOptions => SepWriter => Row => Col(s) => Set/Format
where each continuation flows fluently from the preceding type. For example,
Reader() is an extension method to Sep or SepSpec that returns a
SepReaderOptions. Similarly, Writer() is an extension method to Sep or
SepSpec that returns a SepWriterOptions.
SepReaderOptions
and
SepWriterOptions
are optionally configurable. That and the APIs for reader and writer is covered
in the following sections.
For a complete example, see the example above or the ReadMeTest.cs.
⚠ Note that it is important to understand that Sep Row/Col/Cols are ref
structs
(please follow the ref struct link and understand how this limits the usage of
those). This is due to these types being simple facades or indirections to the
underlying reader or writer. That means you cannot use LINQ or create an array
of all rows like reader.ToArray() as the reader is not IEnumerable<> either
since ref structs cannot be used in interfaces, which is in fact the point.
Hence, you need to parse or copy to different types instead. The same applies to
Col/Cols which point to internal state that is also reused. This is to avoid
repeated allocations for each row and get the best possible performance, while
still defining a well structured and straightforward API that guides users to
relevant functionality. See Why SepReader Is Not IEnumerable and LINQ
Compatible for more.
SepReader API
SepReader API has the following structure (in pseudo-C# code):
1
2
3
4
5
6
7
8
using var reader = Sep.Reader(o => o).FromFile/FromText/From...;
var header = reader.Header;
var _ = header.IndexOf/IndicesOf/NamesStartingWith...;
foreach (var row in reader)
{
var _ = row[colName/colNames].Span/ToString/Parse<T>...;
var _ = row[colIndex/colIndices].Span/ToString/Parse<T>...;
}
That is, to use SepReader follow the points below:
- Optionally define
Sepor use default automatically inferred separator. - Specify reader with optional configuration of
SepReaderOptions. For example, if a csv-file does not have a header this can be configured via:1
Sep.Reader(o => o with { HasHeader = false })
For all options consult the properties on the options type.
- Specify source e.g. file, text (
string),TextWriter, etc. viaFromextension methods. - Optionally access the header. For example, to get all columns starting with
GT_use:1 2
var colNames = header.NamesStarting("GT_"); var colIndices = header.IndicesOf(colNames);
- Enumerate rows. One row at a time.
- Access a column by name or index. Or access multiple columns with names and
indices.
Sepinternally handles pooled allocation and reuse of arrays for multiple columns. - Use
Spanto access the column directly as aReadOnlySpan<char>. Or useToStringto convert to astring. Or useParse<T>whereT : ISpanParsable<T>to parse the columnchars to a specific type.
Why SepReader Is Not IEnumerable and LINQ Compatible
As mentioned earlier Sep only allows enumeration and access to one row at a time
and SepReader.Row is just a simple facade or indirection to the underlying
reader. This is why it is defined as a ref struct. In fact, the following code:
1
2
3
using var reader = Sep.Reader().FromText(text);
foreach (var row in reader)
{ }
can also be rewritten as:
1
2
3
4
5
using var reader = Sep.Reader().FromText(text);
while (reader.MoveNext())
{
var row = reader.Current;
}
where row is just a facade for exposing row specific functionality. That is,
row is still basically the reader underneath. Hence, let’s imagine if
SepReader did implement IEnumerable<SepReader.Row> and the Row was not a
ref struct. Then, you would be able to write something like below:
1
2
using var reader = Sep.Reader().FromText(text);
SepReader.Row[] rows = reader.ToArray();
Given Row is just a facade for the reader, this would be equivalent to
writing:
1
2
using var reader = Sep.Reader().FromText(text);
SepReader[] rows = reader.ToArray();
which hopefully makes it clear why this is not a good thing. The array would
effectively be the reader repeated several times. If this would have to be
supported one would have to allocate memory for each row always, which would
basically be no different than a ReadLine approach as benchmarked in
Comparison Benchmarks.
This is perhaps also the reason why no other efficient .NET CSV parser (known to author) implements an API pattern like Sep, but instead let the reader define all functionality directly and hence only let’s you access the current row and cols on that. This API, however, is in this authors opinion not ideal and can be a bit confusing, which is why Sep is designed like it is. The downside is the above caveat.
If you want to use LINQ or similar you have to first parse or transform the rows
into some other type and enumerate it. This is easy to do and instead of
counting lines you should focus on how such enumeration can be easily expressed
using C# iterators (aka yield return). With local functions this can be done
inside a method like:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
var text = """
Key;Value
A;1.1
B;2.2
""";
var expected = new (string Key, double Value)[] {
("A", 1.1),
("B", 2.2),
};
using var reader = Sep.Reader().FromText(text);
var actual = Enumerate(reader).ToArray();
CollectionAssert.AreEqual(expected, actual);
static IEnumerable<(string Key, double Value)> Enumerate(SepReader reader)
{
foreach (var row in reader)
{
yield return (row["Key"].ToString(), row["Value"].Parse<double>());
}
}
Now if instead refactoring this to something LINQ-compatible by defining a
common Enumerate or similar method it could be:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
var text = """
Key;Value
A;1.1
B;2.2
""";
var expected = new (string Key, double Value)[] {
("A", 1.1),
("B", 2.2),
};
using var reader = Sep.Reader().FromText(text);
var actual = Enumerate(reader,
row => (row["Key"].ToString(), row["Value"].Parse<double>()))
.ToArray();
CollectionAssert.AreEqual(expected, actual);
static IEnumerable<T> Enumerate<T>(SepReader reader, SepReader.RowFunc<T> func)
{
foreach (var row in reader)
{
yield return func(row);
}
}
Which discounting the Enumerate method (which could naturally be an extension
method), does have less boilerplate, but not really more effective lines of
code. The issue here is that this tends to favor factoring code in a way that
can become very inefficient quickly. Consider if one wanted to only enumerate
rows matching a predicate on Key which meant only 1% of rows were to be
enumerated e.g.:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
var text = """
Key;Value
A;1.1
B;2.2
""";
var expected = new (string Key, double Value)[] {
("B", 2.2),
};
using var reader = Sep.Reader().FromText(text);
var actual = Enumerate(reader,
row => (row["Key"].ToString(), row["Value"].Parse<double>()))
.Where(kv => kv.Item1.StartsWith("B", StringComparison.Ordinal))
.ToArray();
CollectionAssert.AreEqual(expected, actual);
static IEnumerable<T> Enumerate<T>(SepReader reader, SepReader.RowFunc<T> func)
{
foreach (var row in reader)
{
yield return func(row);
}
}
This means you are still parsing the double (which is magnitudes slower than
getting just the key) for all rows. Imagine if this was an array of floating
points or similar. Not only would you then be parsing a lot of values you would
also be allocated 99x arrays that aren’t used after filtering with Where.
Instead, you should focus on how to express the enumeration in a way that is both efficient and easy to read. For example, the above could be rewritten as:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
var text = """
Key;Value
A;1.1
B;2.2
""";
var expected = new (string Key, double Value)[] {
("B", 2.2),
};
using var reader = Sep.Reader().FromText(text);
var actual = Enumerate(reader).ToArray();
CollectionAssert.AreEqual(expected, actual);
static IEnumerable<(string Key, double Value)> Enumerate(SepReader reader)
{
foreach (var row in reader)
{
var keyCol = row["Key"];
if (keyCol.Span.StartsWith("B"))
{
yield return (keyCol.ToString(), row["Value"].Parse<double>());
}
}
}
This does not take significantly longer to write and is a lot more efficient (also avoids allocating a string for key for each row) and is easier to debug and perhaps even read. All examples above can be seen in ReadMeTest.cs.
SepWriter API
SepWriter API has the following structure (in pseudo-C# code):
1
2
3
4
5
6
7
using var writer = Sep.Writer(o => o).ToFile/ToText/To...;
foreach (var data in EnumerateData())
{
using var row = writer.NewRow();
var _ = row[colName/colNames].Set/Format<T>...;
var _ = row[colIndex/colIndices].Set/Format<T>...;
}
That is, to use SepWriter follow the points below:
- Optionally define
Sepor use default automatically inferred separator. - Specify writer with optional configuration of
SepWriterOptions. For all options consult the properties on the options type. - Specify destination e.g. file, text (
stringviaStringWriter),TextWriter, etc. viaToextension methods. - MISSING:
SepWritercurrently does not allow you to define the header up front. Instead, header is defined by the order in which column names are accessed/created when defining the row. - Define new rows with
NewRow. ⚠ Be sure to dispose any new rows before starting the next! For convenience Sep provides an overload forNewRowthat takes aSepReader.Rowand copies the columns from that row to the new row:1 2 3 4
using var reader = Sep.Reader().FromText(text); using var writer = reader.Spec.Writer().ToText(); foreach (var readRow in reader) { using var writeRow = writer.NewRow(readRow); }
- Create a column by selecting by name or index. Or multiple columns via
indices and names.
Sepinternally handles pooled allocation and reuse of arrays for multiple columns. - Use
Setto set the column value either as aReadOnlySpan<char>,stringor via an interpolated string. Or useFormat<T>whereT : IFormattableto formatTto the column value. - Row is written when
Disposeis called on the row.Note this is to allow a row to be defined flexibly with both column removal, moves and renames in the future. This is not yet supported.
Limitations and Constraints
Sep is designed to be minimal and fast. As such, it has some limitations and constraints, since these are not needed for the initial intended usage:
- Automatic escaping and unescaping quotes is not supported. Use
Trimextension method to remove surrounding quotes, for example. - Comments
#are not directly supported. You can skip a row by:1 2 3 4 5 6 7 8
foreach (var row in reader) { // Skip row if starts with # if (!row.Span.StartsWith("#")) { // ... } }
This does not allow skipping a header row starting with
#though. SepWriteris not yet fully featured and one cannot skip writing a header currently.
Comparison Benchmarks
To investigate the performance of Sep it is compared to:
- CsvHelper (30.0.1) - the most commonly
used CSV library with a staggering
downloads on NuGet. Fully featured and battle tested.
- Sylvan (1.3.1) - is well-known and has previously been shown to be the fastest CSV libraries for parsing (Sep changes that 😉).
ReadLine/WriteLine- basic naive implementations that read line by line and split on separator. While writing columns, separators and line endings directly. Does not handle quotes or similar correctly.
All benchmarks are run from/to memory either with:
StringReaderorStreamReader + MemoryStreamStringWriterorStreamWriter + MemoryStream
This to avoid confounding factors from reading from or writing to disk.
When using StringReader/StringWriter each char counts as 2 bytes, when
measuring throughput e.g. MB/s. When using StreamReader/StreamWriter
content is UTF-8 encoded and each char typically counts as 1 byte, as content
usually limited to 1 byte per char in UTF-8. Note that in .NET for TextReader
and TextWriter data is converted to/from char, but for reading such
conversion can often be just as fast as Memmove.
By default only StringReader/StringWriter results are shown, if a result is
based on StreamReader/StreamWriter it will be called out. Usually, results
for StreamReader/StreamWriter are in line with StringReader/StringWriter
but with half the throughput due to 1 byte vs 2 bytes. For brevity they are not
shown here.
For all benchmark results, Sep has been defined as the Baseline in
BenchmarkDotNet. This means Ratio will be 1.00
for Sep. For the others Ratio will then show how many times faster Sep is
than that. Or how many times more bytes are allocated in Alloc Ratio.
Disclaimer: Any comparison made is based on a number of preconditions and assumptions. Sep is a new library written from the ground up to use the latest and greatest features in .NET. CsvHelper has a long history and has to take into account backwards compatibility and still supporting older runtimes, so may not be able to easily utilize more recent features. Same goes for Sylvan. Additionally, Sep has a different feature set compared to the two. Performance is a feature, but not the only feature. Keep that in mind when evaluating results.
Runtime and Platforms
The following runtime is used for benchmarking:
NET 7.0.5 (7.0.523.17405)
The following platforms are used for benchmarking:
AMD 5950XX64 Platform Information1 2
OS=Windows 10 (10.0.19044.2846/21H2/November2021Update) AMD Ryzen 9 5950X, 1 CPU, 32 logical and 16 physical cores
Snapdragon® 8cx Gen 3ARM64 Platform Information (courtesy of @xoofx)1 2
OS=Windows 11 (10.0.22621.1702/22H2/2022Update/SunValley2) Snapdragon Compute Platform, 1 CPU, 8 logical and 8 physical cores
Reader Comparison Benchmarks
The following reader scenarios are benchmarked:
- NCsvPerf from The fastest CSV parser in .NET
- Floats as for example in machine learning.
Details for each can be found in the following. However, for each of these 3 different scopes are benchmarked to better assertain the low-level performance of each library and approach and what parts of the parsing consume the most time:
- Row - for this scope only the row is enumerated. That is, for Sep all
that is done is:
1
foreach (var row in reader) { }
this should capture parsing both row and columns but without accessing these. Note that some libraries (like Sylvan) will defer work for columns to when these are accessed.
- Cols - for this scope all rows and all columns are enumerated. If
possible columns are accessed as spans, if not as strings, which then might
mean a string has to be allocated. That is, for Sep this is:
1 2 3 4 5 6 7
foreach (var row in reader) { for (var i = 0; i < row.ColCount; i++) { var span = row[i].Span; } }
- XYZ - finally the full scope is performed which is specific to each of the scenarios.
NCsvPerf PackageAssets Reader Comparison Benchmarks
NCsvPerf from The fastest CSV parser in .NET is a benchmark which in Joel Verhagen own words was defined with:
My goal was to find the fastest low-level CSV parser. Essentially, all I wanted was a library that gave me a string[] for each line where each field in the line was an element in the array.
What is great about this work is it tests a whole of 35 different libraries and approaches to this. Providing a great overview of those and their performance on this specific scenario. Given Sylvan is the fastest of those it is used as the one to beat here, while CsvHelper is used to compare to the most commonly used library.
The source used for this benchmark PackageAssetsBench.cs is a PackageAssets.csv with NuGet package information in 25 columns with rows like:
1
2
3
4
5
75fcf875-017d-4579-bfd9-791d3e6767f0,2020-11-28T01:50:41.2449947+00:00,Akinzekeel.BlazorGrid,0.9.1-preview,2020-11-27T22:42:54.3100000+00:00,AvailableAssets,RuntimeAssemblies,,,net5.0,,,,,,lib/net5.0/BlazorGrid.dll,BlazorGrid.dll,.dll,lib,net5.0,.NETCoreApp,5.0.0.0,,,0.0.0.0
75fcf875-017d-4579-bfd9-791d3e6767f0,2020-11-28T01:50:41.2449947+00:00,Akinzekeel.BlazorGrid,0.9.1-preview,2020-11-27T22:42:54.3100000+00:00,AvailableAssets,CompileLibAssemblies,,,net5.0,,,,,,lib/net5.0/BlazorGrid.dll,BlazorGrid.dll,.dll,lib,net5.0,.NETCoreApp,5.0.0.0,,,0.0.0.0
75fcf875-017d-4579-bfd9-791d3e6767f0,2020-11-28T01:50:41.2449947+00:00,Akinzekeel.BlazorGrid,0.9.1-preview,2020-11-27T22:42:54.3100000+00:00,AvailableAssets,ResourceAssemblies,,,net5.0,,,,,,lib/net5.0/de/BlazorGrid.resources.dll,BlazorGrid.resources.dll,.dll,lib,net5.0,.NETCoreApp,5.0.0.0,,,0.0.0.0
75fcf875-017d-4579-bfd9-791d3e6767f0,2020-11-28T01:50:41.2449947+00:00,Akinzekeel.BlazorGrid,0.9.1-preview,2020-11-27T22:42:54.3100000+00:00,AvailableAssets,MSBuildFiles,,,any,,,,,,build/Microsoft.AspNetCore.StaticWebAssets.props,Microsoft.AspNetCore.StaticWebAssets.props,.props,build,any,Any,0.0.0.0,,,0.0.0.0
75fcf875-017d-4579-bfd9-791d3e6767f0,2020-11-28T01:50:41.2449947+00:00,Akinzekeel.BlazorGrid,0.9.1-preview,2020-11-27T22:42:54.3100000+00:00,AvailableAssets,MSBuildFiles,,,any,,,,,,build/Akinzekeel.BlazorGrid.props,Akinzekeel.BlazorGrid.props,.props,build,any,Any,0.0.0.0,,,0.0.0.0
For Scope = Asset the columns are parsed into a
PackageAsset
class, which consists of 25 properties of which 22 are strings. Each asset is
accumulated into a List<PackageAsset>. Each column is accessed as a string
regardless.
This means this benchmark is dominated by turning columns into strings for the
decently fast parsers. Hence, the fastest libraries in this test employ string
pooling. That is, basically a custom dictionary from ReadOnlySpan<char> to
string, which avoids allocating a new string for repeated values. And as can
be seen in the csv-file there are a lot of repeated values. Both Sylvan and
CsvHelper do this in the benchmark. So does Sep and as with Sep this is an
optional configuration that has to be explicitly enable. For Sep this means the
reader is created with something like:
1
2
3
4
5
6
using var reader = Sep.Reader(o => o with
{
HasHeader = false,
CreateToString = SepToString.PoolPerCol(maximumStringLength: 128),
})
.From(CreateReader());
What is unique for Sep is that it allows defining a pool per column e.g. via
SepToString.PoolPerCol(...). This is based on the fact
that often each column has its own set of values or strings that may be repeated
without any overlap to other columns. This also allows one to define per column
specific handling of ToString behavior. Whether to pool or not. Or even to use
a statically defined pool.
PackageAssets Benchmark Results
The results below show Sep is now the fastest .NET CSV Parser (for this
benchmark on these platforms and machines 😀). While for pure parsing allocating
only a fraction of the memory due to extensive use of pooling and the
ArrayPool<T>.
This is in many aspects due to Sep having extremely optimized string pooling and
optimized hashing of ReadOnlySpan<char>, and thus not really due the the
csv-parsing itself, since that is not a big part of the time consumed. At least
not for a decently fast csv-parser.
AMD 5950X - PackageAssets Benchmark Results (Sep 0.1.0)
| Method | Scope | Rows | Mean | Ratio | MB | MB/s | ns/row | Allocated | Alloc Ratio |
|---|---|---|---|---|---|---|---|---|---|
| Sep______ | Row | 1000000 | 79.59 ms | 1.00 | 583 | 7335.3 | 79.6 | 1.71 KB | 1.00 |
| Sylvan___ | Row | 1000000 | 117.88 ms | 1.48 | 583 | 4952.1 | 117.9 | 135.29 KB | 79.07 |
| ReadLine_ | Row | 1000000 | 266.75 ms | 3.34 | 583 | 2188.5 | 266.7 | 1772445.8 KB | 1,035,950.05 |
| CsvHelper | Row | 1000000 | 1,080.70 ms | 13.59 | 583 | 540.2 | 1080.7 | 20.97 KB | 12.26 |
| Sep______ | Cols | 1000000 | 95.39 ms | 1.00 | 583 | 6119.8 | 95.4 | 1.71 KB | 1.00 |
| Sylvan___ | Cols | 1000000 | 164.63 ms | 1.73 | 583 | 3546.0 | 164.6 | 135.29 KB | 79.07 |
| ReadLine_ | Cols | 1000000 | 281.46 ms | 2.99 | 583 | 2074.2 | 281.5 | 1772445.8 KB | 1,035,950.05 |
| CsvHelper | Cols | 1000000 | 1,757.92 ms | 18.38 | 583 | 332.1 | 1757.9 | 446.63 KB | 261.04 |
| Sep______ | Asset | 1000000 | 753.27 ms | 1.00 | 583 | 775.0 | 753.3 | 266663.53 KB | 1.00 |
| Sylvan___ | Asset | 1000000 | 957.49 ms | 1.27 | 583 | 609.7 | 957.5 | 267014.41 KB | 1.00 |
| ReadLine_ | Asset | 1000000 | 2,091.20 ms | 2.77 | 583 | 279.2 | 2091.2 | 2038832.84 KB | 7.65 |
| CsvHelper | Asset | 1000000 | 2,006.48 ms | 2.66 | 583 | 290.9 | 2006.5 | 266838.11 KB | 1.00 |
Snapdragon® 8cx Gen 3 - PackageAssets Benchmark Results (Sep 0.1.0)
| Method | Scope | Rows | Mean | Ratio | MB | MB/s | ns/row | Allocated | Alloc Ratio |
|---|---|---|---|---|---|---|---|---|---|
| Sep______ | Row | 1000000 | 190.8 ms | 1.00 | 583 | 3060.4 | 190.8 | 1.5 KB | 1.00 |
| Sylvan___ | Row | 1000000 | 447.3 ms | 2.35 | 583 | 1305.0 | 447.3 | 134.61 KB | 89.74 |
| ReadLine_ | Row | 1000000 | 435.4 ms | 2.28 | 583 | 1340.8 | 435.4 | 1772445.91 KB | 1,181,630.61 |
| CsvHelper | Row | 1000000 | 1,524.8 ms | 7.99 | 583 | 382.9 | 1524.8 | 21.09 KB | 14.06 |
| Sep______ | Cols | 1000000 | 226.9 ms | 1.00 | 583 | 2572.6 | 226.9 | 1.83 KB | 1.00 |
| Sylvan___ | Cols | 1000000 | 543.3 ms | 2.39 | 583 | 1074.5 | 543.3 | 134.61 KB | 73.63 |
| ReadLine_ | Cols | 1000000 | 451.7 ms | 1.99 | 583 | 1292.5 | 451.7 | 1772445.91 KB | 969,543.06 |
| CsvHelper | Cols | 1000000 | 2,325.8 ms | 10.25 | 583 | 251.0 | 2325.8 | 446.74 KB | 244.37 |
| Sep______ | Asset | 1000000 | 1,068.1 ms | 1.00 | 583 | 546.6 | 1068.1 | 266668.63 KB | 1.00 |
| Sylvan___ | Asset | 1000000 | 1,519.2 ms | 1.42 | 583 | 384.3 | 1519.2 | 267014.58 KB | 1.00 |
| ReadLine_ | Asset | 1000000 | 2,536.0 ms | 2.38 | 583 | 230.2 | 2536.0 | 2038833.47 KB | 7.65 |
| CsvHelper | Asset | 1000000 | 2,926.3 ms | 2.73 | 583 | 199.5 | 2926.3 | 266842.97 KB | 1.00 |
PackageAssets with Quotes Benchmark Results
NCsvPerf does not examine performance in the face of quotes in the csv. This
is relevant since some libraries like Sylvan will revert to a slower (not SIMD
vectorized) parsing code path if it encounters quotes. Sep was designed to
always use SIMD vectorization no matter what.
Since there are two extra chars to handle per column, it does have a
significant impact on performance, no matter what though. This is expected when
looking at the numbers. For each row of 25 columns, there are 24 separators
(here ,) and one set of line endings (here \r\n). That’s 26 characters.
Adding quotes around each of the 25 columns will add 50 characters or almost
triple the total to 76.
AMD 5950X - PackageAssets with Quotes Benchmark Results (Sep 0.1.0)
| Method | Scope | Rows | Mean | Ratio | MB | MB/s | ns/row | Allocated | Alloc Ratio |
|---|---|---|---|---|---|---|---|---|---|
| Sep______ | Row | 1000000 | 185.0 ms | 1.00 | 667 | 3609.5 | 185.0 | 1.71 KB | 1.00 |
| Sylvan___ | Row | 1000000 | 482.1 ms | 2.60 | 667 | 1384.9 | 482.1 | 135.29 KB | 79.07 |
| ReadLine_ | Row | 1000000 | 310.0 ms | 1.67 | 667 | 2153.8 | 310.0 | 2175928.97 KB | 1,271,775.84 |
| CsvHelper | Row | 1000000 | 1,251.6 ms | 6.76 | 667 | 533.5 | 1251.6 | 20.97 KB | 12.26 |
| Sep______ | Cols | 1000000 | 199.9 ms | 1.00 | 667 | 3340.8 | 199.9 | 1.71 KB | 1.00 |
| Sylvan___ | Cols | 1000000 | 531.5 ms | 2.66 | 667 | 1256.3 | 531.5 | 135.29 KB | 79.07 |
| ReadLine_ | Cols | 1000000 | 329.9 ms | 1.65 | 667 | 2024.0 | 329.9 | 2175928.97 KB | 1,271,775.84 |
| CsvHelper | Cols | 1000000 | 1,954.9 ms | 9.78 | 667 | 341.6 | 1954.9 | 446.63 KB | 261.04 |
| Sep______ | Asset | 1000000 | 897.3 ms | 1.00 | 667 | 744.2 | 897.3 | 266719.75 KB | 1.00 |
| Sylvan___ | Asset | 1000000 | 1,324.3 ms | 1.48 | 667 | 504.2 | 1324.3 | 267020.43 KB | 1.00 |
| ReadLine_ | Asset | 1000000 | 2,736.5 ms | 3.05 | 667 | 244.0 | 2736.5 | 2442317.8 KB | 9.16 |
| CsvHelper | Asset | 1000000 | 2,270.0 ms | 2.53 | 667 | 294.1 | 2270.0 | 266832.73 KB | 1.00 |
Snapdragon® 8cx Gen 3 - PackageAssets with Quotes Benchmark Results (Sep 0.1.0)
| Method | Scope | Rows | Mean | Ratio | MB | MB/s | ns/row | Allocated | Alloc Ratio |
|---|---|---|---|---|---|---|---|---|---|
| Sep______ | Row | 1000000 | 364.5 ms | 1.00 | 667 | 1832.0 | 364.5 | 1.83 KB | 1.00 |
| Sylvan___ | Row | 1000000 | 605.2 ms | 1.65 | 667 | 1103.3 | 605.2 | 134.61 KB | 73.63 |
| ReadLine_ | Row | 1000000 | 524.2 ms | 1.43 | 667 | 1273.7 | 524.2 | 2175929.09 KB | 1,190,251.81 |
| CsvHelper | Row | 1000000 | 1,910.2 ms | 5.24 | 667 | 349.5 | 1910.2 | 21.09 KB | 11.53 |
| Sep______ | Cols | 1000000 | 391.2 ms | 1.00 | 667 | 1707.0 | 391.2 | 1.83 KB | 1.00 |
| Sylvan___ | Cols | 1000000 | 726.9 ms | 1.86 | 667 | 918.6 | 726.9 | 134.61 KB | 73.63 |
| ReadLine_ | Cols | 1000000 | 535.3 ms | 1.37 | 667 | 1247.4 | 535.3 | 2175929.09 KB | 1,190,251.81 |
| CsvHelper | Cols | 1000000 | 2,720.9 ms | 6.93 | 667 | 245.4 | 2720.9 | 446.74 KB | 244.37 |
| Sep______ | Asset | 1000000 | 1,281.5 ms | 1.00 | 667 | 521.0 | 1281.5 | 266718.98 KB | 1.00 |
| Sylvan___ | Asset | 1000000 | 1,681.9 ms | 1.31 | 667 | 397.0 | 1681.9 | 267020.91 KB | 1.00 |
| ReadLine_ | Asset | 1000000 | 3,393.8 ms | 2.66 | 667 | 196.7 | 3393.8 | 2442317.49 KB | 9.16 |
| CsvHelper | Asset | 1000000 | 3,302.2 ms | 2.57 | 667 | 202.2 | 3302.2 | 266842.28 KB | 1.00 |
Floats Reader Comparison Benchmarks
The FloatsReaderBench.cs
benchmark demonstrates what Sep is built for. Namely parsing 32-bit floating
points or features as in machine learning. Here a simple CSV-file is randomly
generated with N ground truth values, N predicted result values and some
typical extra columns leading that, but which aren’t used as such in the
benchmark. N = 20 here. For example:
1
2
3
4
5
Set;FileName;DataSplit;GT_Feature0;GT_Feature1;GT_Feature2;GT_Feature3;GT_Feature4;GT_Feature5;GT_Feature6;GT_Feature7;GT_Feature8;GT_Feature9;GT_Feature10;GT_Feature11;GT_Feature12;GT_Feature13;GT_Feature14;GT_Feature15;GT_Feature16;GT_Feature17;GT_Feature18;GT_Feature19;RE_Feature0;RE_Feature1;RE_Feature2;RE_Feature3;RE_Feature4;RE_Feature5;RE_Feature6;RE_Feature7;RE_Feature8;RE_Feature9;RE_Feature10;RE_Feature11;RE_Feature12;RE_Feature13;RE_Feature14;RE_Feature15;RE_Feature16;RE_Feature17;RE_Feature18;RE_Feature19
SetCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCC;wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwww.png;Train;0.52276427;0.16843422;0.26259267;0.7244084;0.51292276;0.17365117;0.76125056;0.23458846;0.2573214;0.50560355;0.3202332;0.3809696;0.26024464;0.5174511;0.035318818;0.8141374;0.57719684;0.3974705;0.15219308;0.09011261;0.70515215;0.81618196;0.5399706;0.044147138;0.7111546;0.14776127;0.90621275;0.6925897;0.5164137;0.18637845;0.041509967;0.30819967;0.5831603;0.8210651;0.003954861;0.535722;0.8051845;0.7483589;0.3845737;0.14911908
SetAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA;mmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmm.png;Test;0.6264564;0.11517637;0.24996082;0.77242833;0.2896067;0.6481459;0.14364648;0.044498358;0.6045593;0.51591337;0.050794687;0.42036617;0.7065823;0.6284636;0.21844554;0.013253775;0.36516154;0.2674384;0.06866083;0.71817476;0.07094294;0.46409357;0.012033525;0.7978093;0.43917948;0.5134962;0.4995968;0.008952909;0.82883793;0.012896823;0.0030740085;0.063773096;0.6541431;0.034539033;0.9135142;0.92897075;0.46119377;0.37533295;0.61660606;0.044443816
SetBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB;lllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllll.png;Validation;0.7922863;0.5323656;0.400699;0.29737252;0.9072584;0.58673894;0.73510516;0.019412167;0.88168067;0.9576787;0.33283427;0.7107;0.1623628;0.10314285;0.4521515;0.33324885;0.7761104;0.14854911;0.13469358;0.21566042;0.59166247;0.5128394;0.98702157;0.766223;0.67204326;0.7149494;0.2894748;0.55206;0.9898286;0.65083236;0.02421702;0.34540752;0.92906284;0.027142895;0.21974725;0.26544374;0.03848049;0.2161237;0.59233844;0.42221397
SetAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA;ssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssss.png;Train;0.10609442;0.32130885;0.32383907;0.7511514;0.8258279;0.00904226;0.0420841;0.84049565;0.8958947;0.23807365;0.92621964;0.8452882;0.2794469;0.545344;0.63447595;0.62532926;0.19230893;0.29726416;0.18304513;0.029583583;0.23084833;0.93346167;0.98742676;0.78163713;0.13521992;0.8833956;0.18670778;0.29476836;0.5599867;0.5562107;0.7124796;0.121927656;0.5981778;0.39144602;0.88092715;0.4449142;0.34820423;0.96379805;0.46364686;0.54301775
For Scope=Floats the benchmark will parse the features as two spans of
floats; one for ground truth values and one for predicted result values. Then
calculates the mean squared error (MSE) of those as an example. For Sep this
code is succinct and still incredibly efficient:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
using var reader = Sep.Reader().From(Reader.CreateReader());
var groundTruthColNames = reader.Header.NamesStartingWith("GT_");
var resultColNames = groundTruthColNames.Select(n =>
n.Replace("GT_", "RE_", StringComparison.Ordinal))
.ToArray();
var sum = 0.0;
var count = 0;
foreach (var row in reader)
{
var gts = row[groundTruthColNames].Parse<float>();
var res = row[resultColNames].Parse<float>();
sum += MeanSquaredError(gts, res);
++count;
}
return sum / count;
Note how one can access and parse multiple columns easily while there are no repeated allocations for the parsed floating points. Sep internally handles a pool of arrays for handling multiple columns and returns spans for them.
The benchmark is based on an assumption of accessing columns by name per row. Ideally, one would look up the indices of the columns by name before enumerating rows, but this is a repeated nuisance to have to handle and Sep was built to avoid this. Hence, the comparison is based on looking up by name for each, even if this ends up adding a bit more code in the benchmark for other approaches.
As can be seen below, the actual low level parsing of the separated values is a tiny part of the total runtime for Sep for which the run time is dominated by parsing the floating points. Since Sep uses csFastFloat for an integrated fast floating point parser, it is >2x faster than Sylvan for example. If using Sylvan one may consider using csFastFloat if that is an option.
CsvHelper suffers from the fact that one can only access the column as a string
so this has to be allocated for each column (ReadLine by definition always
allocates a string per column). Still CsvHelper is significantly slower than the
naive ReadLine approach. With Sep being >3.8x faster than CsvHelper.
It is a testament to how good the .NET and the .NET GC is that the ReadLine is pretty good compared to CsvHelper regardless of allocating a lot of strings.
AMD 5950X - Floats Benchmark Results (Sep 0.1.0)
| Method | Scope | Rows | Mean | Ratio | MB | MB/s | ns/row | Allocated | Alloc Ratio |
|---|---|---|---|---|---|---|---|---|---|
| Sep______ | Row | 100000 | 15.22 ms | 1.00 | 109 | 7160.5 | 152.2 | 1.49 KB | 1.00 |
| Sylvan___ | Row | 100000 | 21.86 ms | 1.44 | 109 | 4986.5 | 218.6 | 139.46 KB | 93.34 |
| ReadLine_ | Row | 100000 | 55.33 ms | 3.62 | 109 | 1970.1 | 553.3 | 359865.38 KB | 240,851.07 |
| CsvHelper | Row | 100000 | 163.40 ms | 10.74 | 109 | 667.2 | 1634.0 | 20.6 KB | 13.79 |
| Sep______ | Cols | 100000 | 17.20 ms | 1.00 | 109 | 6336.7 | 172.0 | 1.49 KB | 1.00 |
| Sylvan___ | Cols | 100000 | 29.40 ms | 1.71 | 109 | 3708.4 | 294.0 | 139.46 KB | 93.34 |
| ReadLine_ | Cols | 100000 | 55.66 ms | 3.24 | 109 | 1958.7 | 556.6 | 359865.38 KB | 240,851.07 |
| CsvHelper | Cols | 100000 | 171.61 ms | 10.00 | 109 | 635.2 | 1716.1 | 113699.73 KB | 76,097.08 |
| Sep______ | Floats | 100000 | 138.29 ms | 1.00 | 109 | 788.3 | 1382.9 | 8.71 KB | 1.00 |
| Sylvan___ | Floats | 100000 | 291.50 ms | 2.11 | 109 | 374.0 | 2915.0 | 51.53 KB | 5.92 |
| ReadLine_ | Floats | 100000 | 323.53 ms | 2.34 | 109 | 336.9 | 3235.3 | 359871.8 KB | 41,335.81 |
| CsvHelper | Floats | 100000 | 549.80 ms | 3.98 | 109 | 198.3 | 5498.0 | 87694.13 KB | 10,072.77 |
Snapdragon® 8cx Gen 3 - Floats Benchmark Results (Sep 0.1.0)
| Method | Scope | Rows | Mean | Ratio | MB | MB/s | ns/row | Allocated | Alloc Ratio |
|---|---|---|---|---|---|---|---|---|---|
| Sep______ | Row | 100000 | 36.55 ms | 1.00 | 109 | 2982.5 | 365.5 | 1.51 KB | 1.00 |
| Sylvan___ | Row | 100000 | 98.62 ms | 2.70 | 109 | 1105.4 | 986.2 | 138.18 KB | 91.76 |
| ReadLine_ | Row | 100000 | 85.72 ms | 2.35 | 109 | 1271.7 | 857.2 | 359865.39 KB | 238,976.75 |
| CsvHelper | Row | 100000 | 225.93 ms | 6.25 | 109 | 482.5 | 2259.3 | 20.61 KB | 13.69 |
| Sep______ | Cols | 100000 | 39.58 ms | 1.00 | 109 | 2754.2 | 395.8 | 1.51 KB | 1.00 |
| Sylvan___ | Cols | 100000 | 110.61 ms | 2.79 | 109 | 985.5 | 1106.1 | 138.18 KB | 91.76 |
| ReadLine_ | Cols | 100000 | 87.29 ms | 2.20 | 109 | 1248.9 | 872.9 | 359865.39 KB | 238,976.75 |
| CsvHelper | Cols | 100000 | 234.58 ms | 5.89 | 109 | 464.7 | 2345.8 | 113699.75 KB | 75,504.89 |
| Sep______ | Floats | 100000 | 188.05 ms | 1.00 | 109 | 579.7 | 1880.5 | 8.72 KB | 1.00 |
| Sylvan___ | Floats | 100000 | 483.76 ms | 2.57 | 109 | 225.3 | 4837.6 | 50.25 KB | 5.76 |
| ReadLine_ | Floats | 100000 | 477.34 ms | 2.54 | 109 | 228.4 | 4773.4 | 359871.81 KB | 41,280.24 |
| CsvHelper | Floats | 100000 | 719.83 ms | 3.83 | 109 | 151.4 | 7198.3 | 87694.14 KB | 10,059.24 |
SepReader Deep Dive
At the core of SepReader is code for finding the special char’s that are
used to structure the separated values. That is, ,, \n, \r, ". Depending
on the separator used. Here it’s comma. Sep contains several SIMD-vectorized
approaches to find these (implementations of ISepCharsFinder). On x64 the
currently fastest is an AVX2
approach
which is JIT’ed to something like the fairly tight assembly shown below. With
comments added here.
The finders basically get a char[] as input and outputs new packed char (as
byte) and position in an int[]. That is if c defines character and p
defines position this is packed as:
1
0bcccc_cccc_pppp_pppp_pppp_pppp_pppp_pppp
This limits both the special chars supported to < 255 and the maximum row length to 2^24 = 16 MB, which is considered a design choice.
I don’t know if this packing is especially beneficial but the idea is to reduce memory and, hence, cache usage. This char+position “index” is then used to parse one row (and it’s columns) at a time.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
// Load registers filled with the 4 different special chars as bytes
C5FD104128 vmovupd ymm0, ymmword ptr[rcx+28H]
C5FD104948 vmovupd ymm1, ymmword ptr[rcx+48H]
C5FD105168 vmovupd ymm2, ymmword ptr[rcx+68H]
C5FD109988000000 vmovupd ymm3, ymmword ptr[rcx+88H]
// Load separator into a register and shift left 24 bits for
// subsequent packing of found char with position in those 24 bits.
0FB64908 movzx rcx, byte ptr [rcx+08H]
C1E118 shl ecx, 24
453BC1 cmp r8d, r9d
0F8DA4000000 jge G_M000_IG13
G_M000_IG03: ;; offset=0070H
// Load 16 chars (16-bit per char) into a register
C5FD1022 vmovupd ymm4, ymmword ptr[rdx]
// Pack those 16 with another 16 chars loaded from memory,
// as unsigned bytes with chars >255 saturated to 255.
C5DD676220 vpackuswb ymm4, ymm4, ymmword ptr[rdx+20H]
// Permute the packed bytes since packing shuffles the order
C4E3FD00E4D8 vpermq ymm4, ymm4, -40
// Compare bytes to the special chars to be found as bytes
C5DD74E8 vpcmpeqb ymm5, ymm4, ymm0
C5DD74F1 vpcmpeqb ymm6, ymm4, ymm1
C5DD74FA vpcmpeqb ymm7, ymm4, ymm2
C5DD74E3 vpcmpeqb ymm4, ymm4, ymm3
// Or the "masks" of found characters
C5D5EBEE vpor ymm5, ymm5, ymm6
C5D5EBEF vpor ymm5, ymm5, ymm7
C5D5EBEC vpor ymm5, ymm5, ymm4
// Get a 32-bit mask via move mask with 1-bit per byte
// indicating if that position has any special char.
C5FDD7FD vpmovmskb edi, ymm5
// If there are no special chars, jump to continuation
85FF test edi, edi
7450 je SHORT G_M000_IG10
G_M000_IG04: ;; offset=00A3H
// Check if all special chars are separators
C5FDD7DC vpmovmskb ebx, ymm4
3BDF cmp ebx, edi
// If not jump to handling of any special char, otherwise
// continue with specific handling of separators only.
751E jne SHORT G_M000_IG07
// Prepare packed representation of found separator
8BF9 mov edi, ecx
410BF8 or edi, r8d
align [0 bytes for IG05]
G_M000_IG05: ;; offset=00B0H
33ED xor ebp, ebp
// Trailing zero count for first bit offset in mask
F30FBCEB tzcnt ebp, ebx
// Reset the first bit
C4E260F3CB blsr ebx, ebx
// Add found offset to packed representation
03EF add ebp, edi
// Move to char+position array
892E mov dword ptr [rsi], ebp
// Increment char+position pointer
4883C604 add rsi, 4
// Continue if more in mask
85DB test ebx, ebx
75E9 jne SHORT G_M000_IG05
G_M000_IG06: ;; offset=00C7H
EB24 jmp SHORT G_M000_IG09
align [0 bytes for IG08]
G_M000_IG07: ;; offset=00C9H
G_M000_IG08: ;; offset=00C9H
// Below is similar to above for separator but where
// the character has to be read from memory and then
// combined into the packed representation.
33DB xor ebx, ebx
F30FBCDF tzcnt ebx, edi
C4E240F3CF blsr edi, edi
4863EB movsxd rbp, ebx
0FB72C6A movzx rbp, word ptr [rdx+2*rbp]
4103D8 add ebx, r8d
C1E518 shl ebp, 24
0BDD or ebx, ebp
891E mov dword ptr [rsi], ebx
4883C604 add rsi, 4
85FF test edi, edi
75DC jne SHORT G_M000_IG08
G_M000_IG09: ;; offset=00EDH
// Check if room for more in char+position array
483BC6 cmp rax, rsi
7213 jb SHORT G_M000_IG12
G_M000_IG10: ;; offset=00F2H
// Increment for next set of 32 chars if there are more
4183C020 add r8d, 32
4883C240 add rdx, 64
453BC1 cmp r8d, r9d
0F8C6DFFFFFF jl G_M000_IG03
If one looks at the PackageAssets
Benchmark above and the
full Asset load with Visual Studio’s profiler, the SIMD-code accounts for
5.51% of total CPU usage. Below shows CPU usage sorted by Self CPU. Compare
this to StringReader.Read at 3.72%, which is copying from the StringReader
string to the internal char[] in the SepReader. Overall, most time here is
spent on the string pooling (getting hash, looking up string) and the allocation
and creation of the PackageAsset instances.
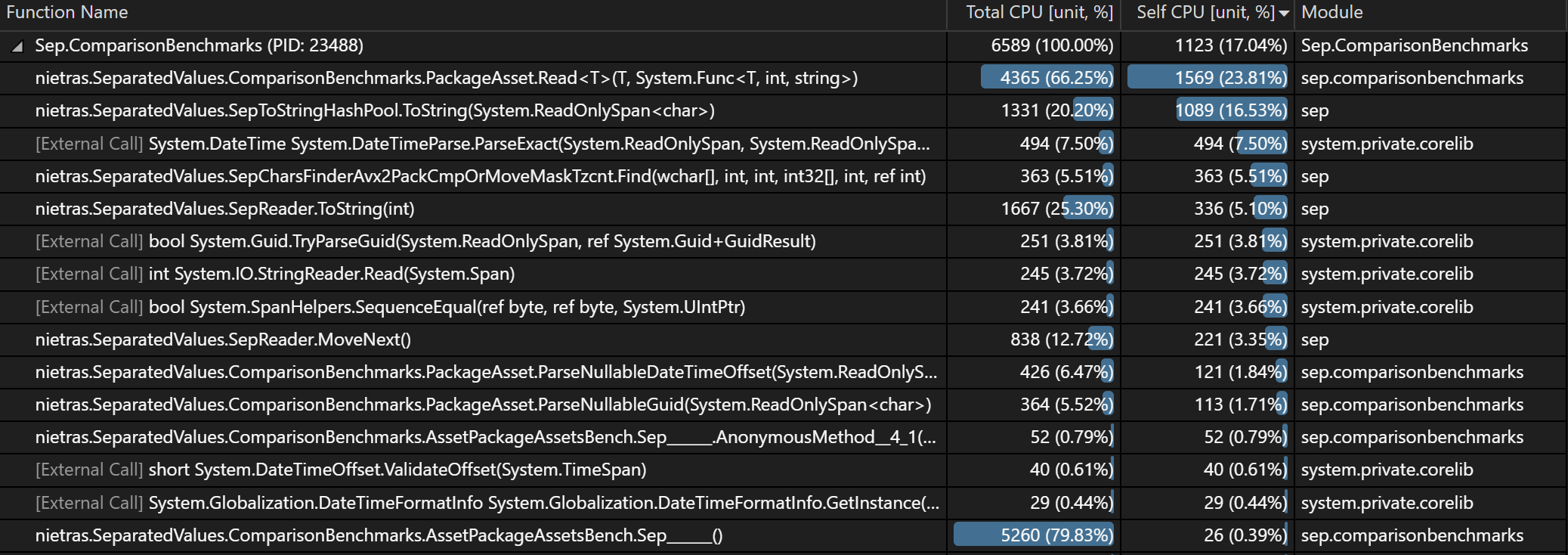
Below one can see the CPU usage but for just parsing the Rows for the same.
Here you will see the SIMD-code accounts for about 39% of the CPU usage. A bit
more than the StringReader memory copying, hence the SIMD-code is close to
being just as fast as memory copying. MoveNext is pretty much the rest of what
Sep has to do to parse a row. I.e. use the char+position index to find
separators to mark column ends and line endings to mark end of a row.

For any real work load, however, most CPU usage will be related to the actual “user” code, not the CSV parsing, that’s what you get with the world’s fastest .NET CSV parser 🚀