Sep 0.3.0 - Unescape Support (still the Most Efficient .NET CSV Parser)
Alright, alright, alright! This blog post announces the release of Sep 0.3.0 with unescape support. Sooner than I had imagined given we don’t really need it, and primarily as a consequence of pride and vanity. Not the least given that in Joel Verhagen’s updated blog post, The fastest CSV parser in .NET, there is a big fat caveat attached to Sep:
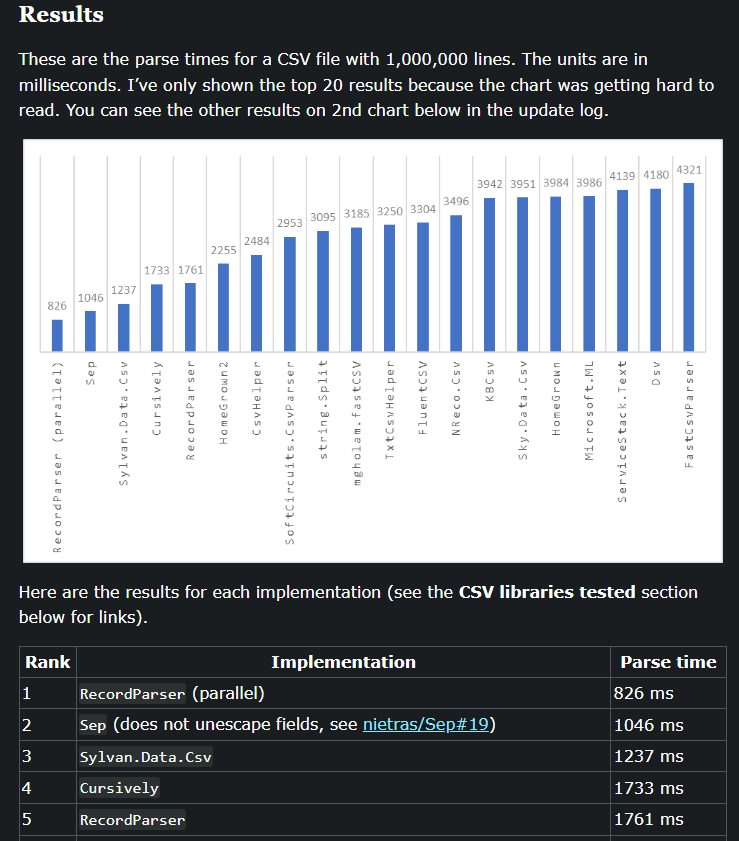
Well, now Sep can unescape if you ask it to with the Unescape option. Here I
will focus on the new unescape support, but other releases after 0.2.3 contain a number of changes including
some minor breaking changes to make the API more consistent with regards to
naming. See Releases for notes on
those changes. Notably the README now contains
the full public API definition courtesy of the
PublicApiGenerator
library at the bottom.
Unescaping
To enable unescaping all you have to do is write something like:
1
2
3
using var reader = Sep
.Reader(o => o with { Unescape = true })
.FromText(text);
And Sep will then unquote and unescape quotes in columns upon access.
The algorithm employed by Sep is fairly simple. If a column starts with a quote
then the two outermost quotes are removed and every second inner quote is
removed. Note that unquote/unescape happens in-place, which means the
SepReader.Row.Span will be modified and contain “garbage” state after
unescaped cols before next col. This is for efficiency to avoid allocating
secondary memory for unescaped columns. Header columns/names will also be
unescaped.
This may not suite everyones needs. This mainly relates to how invalidly escaped columns are handled, so lets take a look at a comparison of unescaped output from CsvHelper, Sylvan and Sep as is also documented in the Sep README.
The below table tries to summarize the behavior of Sep vs CsvHelper and Sylvan. Note that all do the same for valid input. There are differences for how invalid input is handled. For Sep the design choice has been based on not wanting to throw exceptions and to use a principle that is both reasonably fast and simple.
| Input | Valid | CsvHelper | CsvHelper¹ | Sylvan | Sep² |
|---|---|---|---|---|---|
a |
True | a |
a |
a |
a |
"" |
True | ||||
"""" |
True | " |
" |
" |
" |
"""""" |
True | "" |
"" |
"" |
"" |
"a" |
True | a |
a |
a |
a |
"a""a" |
True | a"a |
a"a |
a"a |
a"a |
"a""a""a" |
True | a"a"a |
a"a"a |
a"a"a |
a"a"a |
a""a |
False | EXCEPTION | a""a |
a""a |
a""a |
a"a"a |
False | EXCEPTION | a"a"a |
a"a"a |
a"a"a |
·""· |
False | EXCEPTION | ·""· |
·""· |
·""· |
·"a"· |
False | EXCEPTION | ·"a"· |
·"a"· |
·"a"· |
·"" |
False | EXCEPTION | ·"" |
·"" |
·"" |
·"a" |
False | EXCEPTION | ·"a" |
·"a" |
·"a" |
a"""a |
False | EXCEPTION | a"""a |
a"""a |
a"""a |
"a"a"a" |
False | EXCEPTION | aa"a" |
a"a"a |
aa"a |
""· |
False | EXCEPTION | · |
" |
· |
"a"· |
False | EXCEPTION | a· |
a" |
a· |
"a"""a |
False | EXCEPTION | aa |
EXCEPTION | a"a |
"a"""a" |
False | EXCEPTION | aa" |
a"a<NULL> |
a"a" |
""a" |
False | EXCEPTION | a" |
"a |
a" |
"a"a" |
False | EXCEPTION | aa" |
a"a |
aa" |
""a"a"" |
False | EXCEPTION | a"a"" |
"a"a" |
a"a" |
""" |
False | EXCEPTION | " |
||
""""" |
False | " |
" |
EXCEPTION | "" |
· (middle dot) is whitespace to make this visible
¹ CsvHelper with BadDataFound = null
² Sep with Unescape = true in SepReaderOptions
If the Sep output does not suite your needs consider using one of the other
great CSV libraries out there, or use the Col.Span property and do your own
unescaping.
Now how is perf then if unescaping is enabled? It’s still great, but of course there is a cost. For all the gory details and performance and platforms check the README, here I will focus on performance on ARM since that is often overlooked even in this day and age.
Neoverse.N1 - PackageAssets with Quotes Benchmark Results (Sep 0.3.0.0, Sylvan 1.3.5.0, CsvHelper 30.0.1.0)
| Method | Scope | Rows | Mean | Ratio | MB | MB/s | ns/row | Allocated | Alloc Ratio |
|---|---|---|---|---|---|---|---|---|---|
| Sep____ | Row | 50000 | 24.35 ms | 1.00 | 33 | 1366.9 | 487.0 | 941 B | 1.00 |
| Sep_Unescape | Row | 50000 | 24.21 ms | 0.99 | 33 | 1374.7 | 484.2 | 941 B | 1.00 |
| Sylvan___ | Row | 50000 | 39.92 ms | 1.64 | 33 | 833.6 | 798.5 | 6288 B | 6.68 |
| ReadLine_ | Row | 50000 | 45.96 ms | 1.89 | 33 | 724.1 | 919.3 | 111389508 B | 118,373.55 |
| CsvHelper | Row | 50000 | 106.99 ms | 4.40 | 33 | 311.1 | 2139.8 | 21272 B | 22.61 |
| Sep____ | Cols | 50000 | 26.96 ms | 1.00 | 33 | 1234.3 | 539.3 | 869 B | 1.00 |
| Sep_Unescape | Cols | 50000 | 28.60 ms | 1.06 | 33 | 1163.6 | 572.1 | 953 B | 1.10 |
| Sylvan___ | Cols | 50000 | 45.48 ms | 1.69 | 33 | 731.8 | 909.6 | 6318 B | 7.27 |
| ReadLine_ | Cols | 50000 | 45.95 ms | 1.70 | 33 | 724.4 | 918.9 | 111389521 B | 128,181.27 |
| CsvHelper | Cols | 50000 | 152.46 ms | 5.65 | 33 | 218.3 | 3049.1 | 457328 B | 526.27 |
| Sep____ | Asset | 50000 | 83.86 ms | 1.00 | 33 | 396.9 | 1677.2 | 14139912 B | 1.00 |
| Sep_Unescape | Asset | 50000 | 79.99 ms | 0.96 | 33 | 416.1 | 1599.9 | 14132628 B | 1.00 |
| Sylvan___ | Asset | 50000 | 110.29 ms | 1.31 | 33 | 301.8 | 2205.9 | 14298320 B | 1.01 |
| ReadLine_ | Asset | 50000 | 178.89 ms | 2.13 | 33 | 186.1 | 3577.7 | 125240480 B | 8.86 |
| CsvHelper | Asset | 50000 | 182.59 ms | 2.18 | 33 | 182.3 | 3651.7 | 14308800 B | 1.01 |
As can be seen above Sep is ~1.6 faster than Sylvan (the second most efficient CSV parser with many features Sep does not have) at the lowest level of parsing rows or just cols. For that case the impact of unescaping is a minor 6%, but once you then get to the top level test of parsing package assets information this speeds up the benchmark since removing quotes reduces hashing costs and therefore pooling cost employed in this benchmark. Note that Sep is 4-5x faster than CsvHelper. The read line approach does not unescape so is only there as a form of basic baseline. I hope this addresses that big fat caveat.
Efficiency vs Parallization
There is one big “issue” still, though, and that is that Sep isn’t #1 in the above ranking, since there now is a multi-threaded contender, RecordParser! Nice! I always prefer improving efficiency first before going to multi-threading, but parallizing CSV “parsing”, with parsing in quotes since it’s more related to the parsing of text after CSV parsing, for real work loads is a real need that we have at my company too, and it is relevant for machine learning where you can have very big CSV files with lots of floats.
I have tried reproducing the results on my own machine, but in my testing Sep still outperforms (significantly) RecordParser on a 16c/32t where Sep uses just 1 thread as shown below:
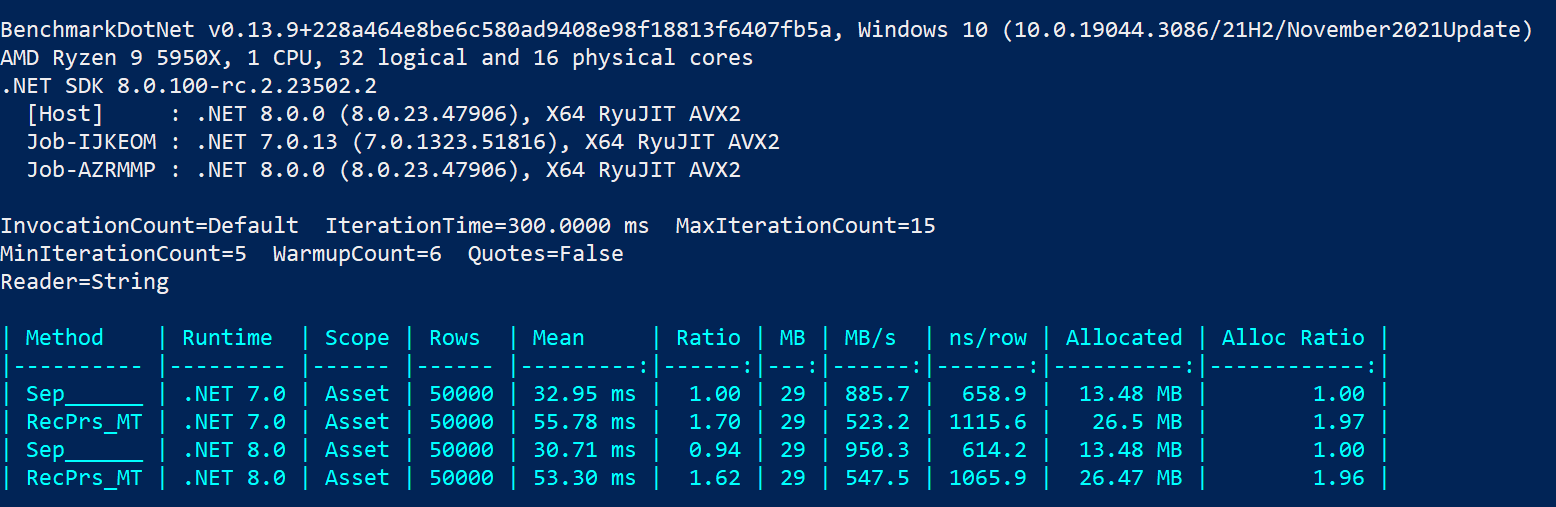
where RecPrs_MT is RecordParser in parallized mode. Of course, my benchmark
uses fewer rows and is on a different machine. As always do your own benchmarks
for your own specific scenario.
I have been working on parallization with a focus on float parsing for Sep, but it wasn’t as efficient as I wanted, so I tabled in. Given the competition I will revisit that and hopefully address that in the next Sep post. Until then I hope you are enjoying the new .NET 8 release, as well 🚀