Sep 0.4.0-0.5.2 - Insanely Fast Single- & Multi-threaded .NET CSV Parsing (up to 35x faster than CsvHelper)
As mentioned at the end of Sep 0.3.0 - Unescape Support (still the Most Efficient .NET CSV Parser) there was one big “issue” remaining with regards to Sep being the world’s fastest .NET CSV parser and that was parallelization. Below is a sneak peek of how insanely fast Sep is now, read on for more.
On January 1st, 2024 Sep 0.4.0 was released to address the lack of
parallelization. This was a major release with a rewrite of the parser to
efficiently support multi-threading. Surfaced as a new simple to use extension
method ParallelEnumerate that allows for parallel enumeration of parsed data
from rows like:
1
2
3
using var reader = Sep.Reader().FromFile("very-long.csv");
var results = reader.ParallelEnumerate(ParseRow);
foreach (var result in results) { Handle(result); }
For more on the API see the README on GitHub. Since 0.4.0 there have been multiple other releases (latest being 0.5.2) including some breaking changes to make the API more consistent. See Releases for notes on those changes which also include various minor new features and not the least a buffer overrun bug fix, so be sure to update to the currently latest version.
In this blog post I will focus on the new multi-threading support and the insane performance Sep now offers. Not the least Sep is now “officially” the world’s fastest .NET CSV parser now that Joel Verhagen’s has updated his blog post The fastest CSV parser in .NET based on Sep 0.4.0.
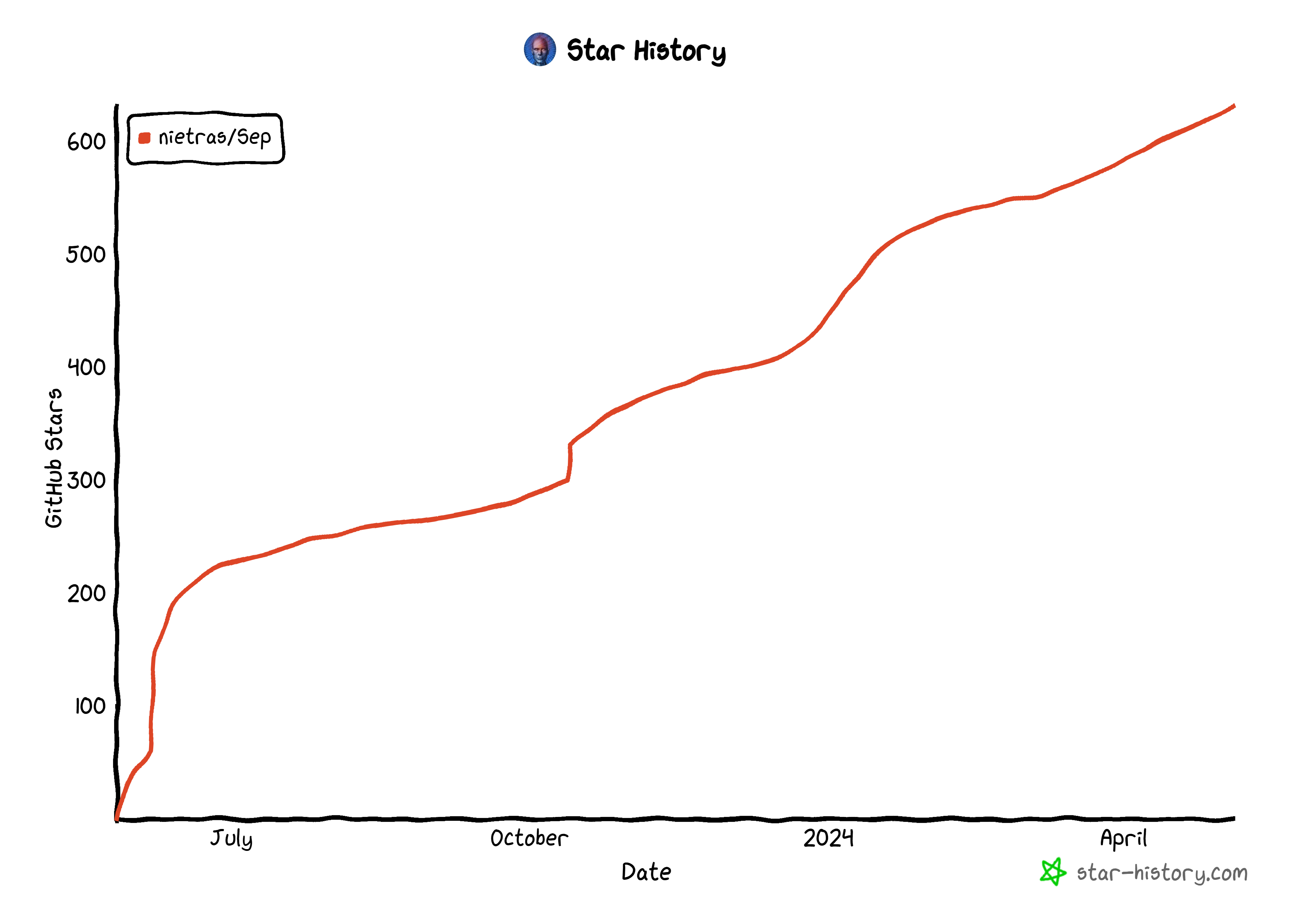
Before going into that, a thank you to all out there that have given Sep a try, filed issues and to all that have given Sep a star ⭐ on GitHub. It is much appreciated! Since introducing Sep in June 2023 Sep now has ⭐623 and 1.4 million downloads on nuget.org. The latter number is, though, not really representative of Sep’s usage but rather a single well-appreciated user with a lot of daily CI runs. Thanks for boosting Sep numbers 🙏
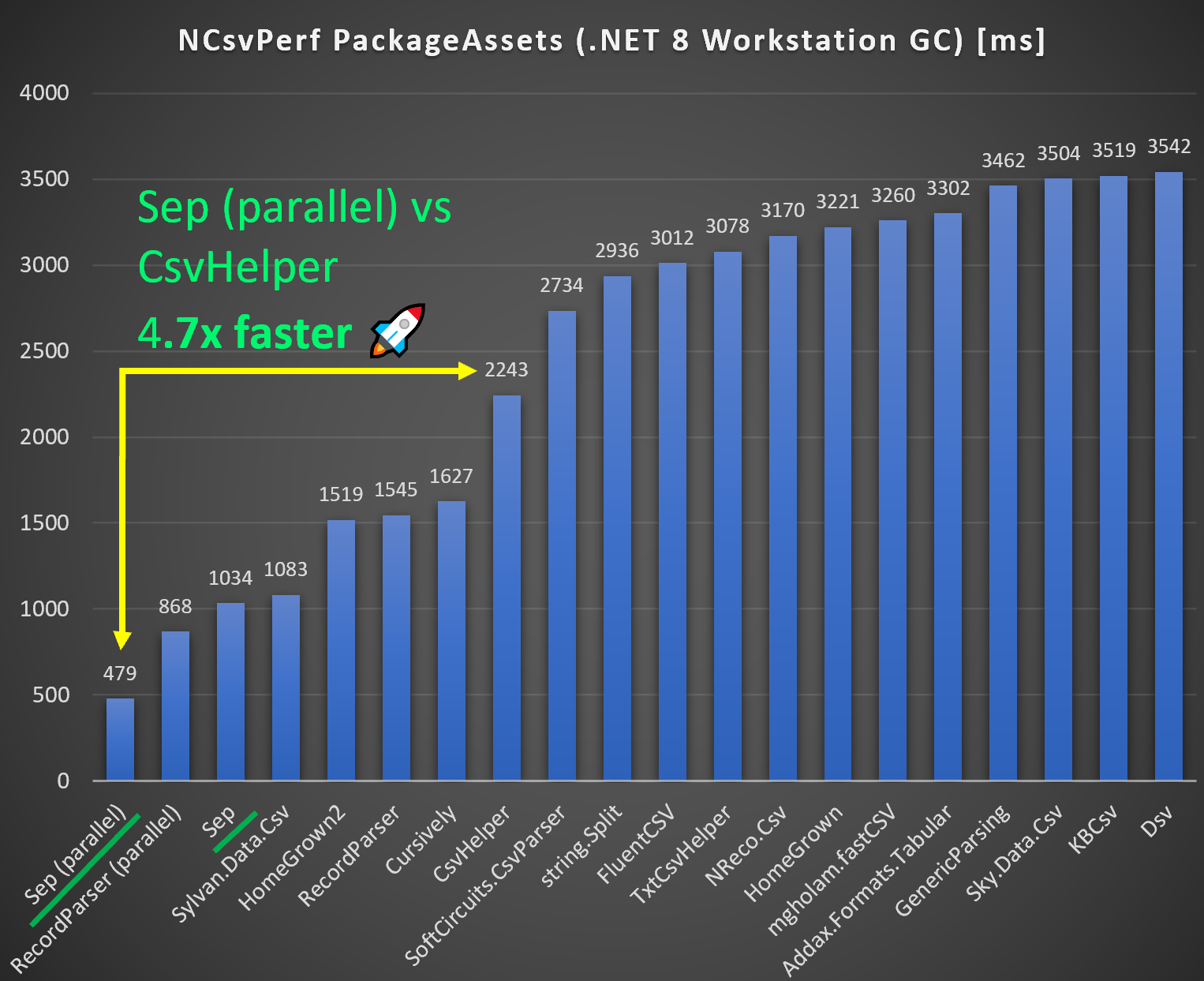
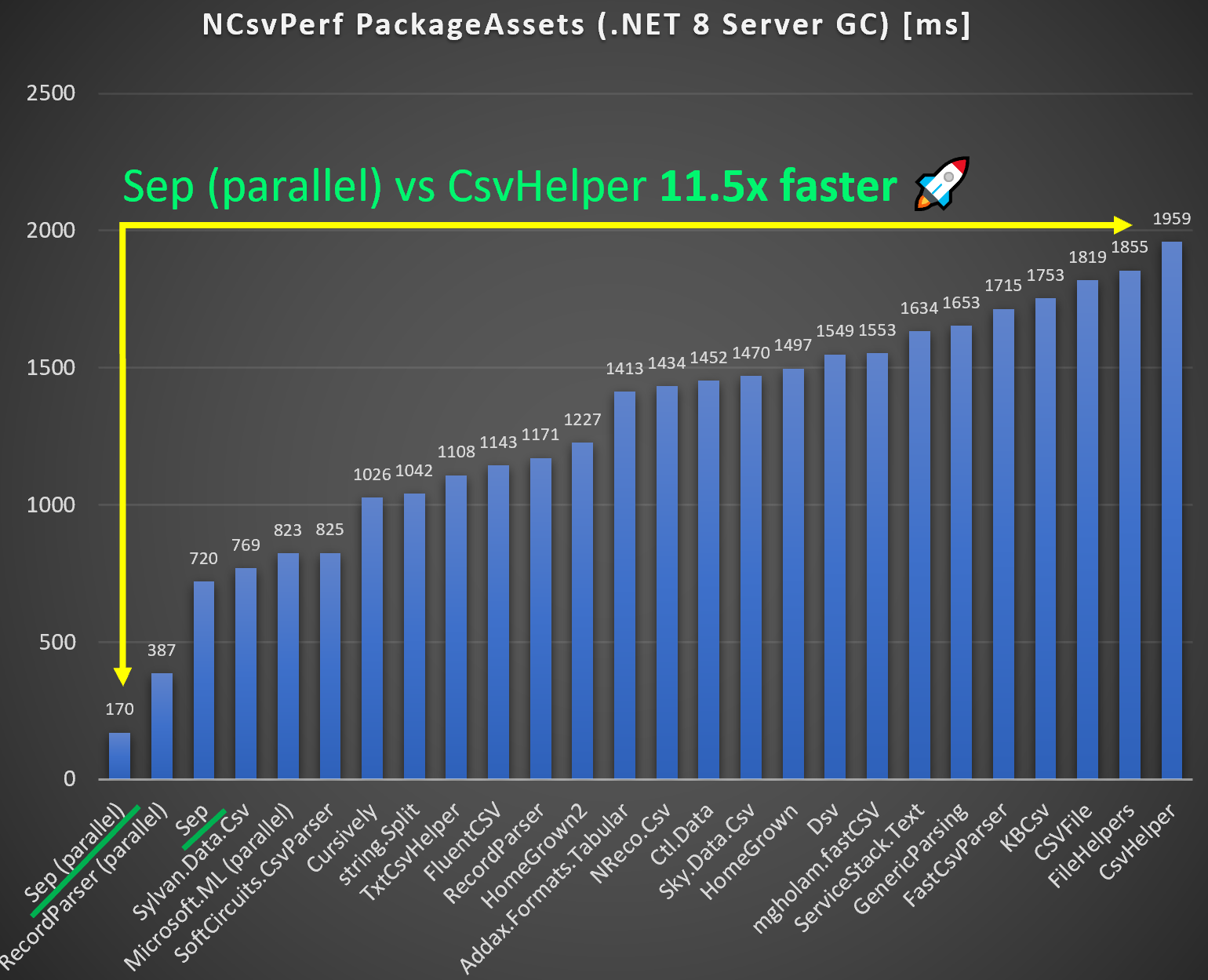
NCsvPerf Package Assets Benchmark - Top 20 Fastest .NET CSV Parsers
Using the numbers from Joel Verhagen’s blog
post the below charts compare Sep to the other top 20 fastest CSV parsers on
.NET 8 with either Workstation GC or Server
GC.
The impact of using server GC is tremendous due the the way the NCsvPerf package
assets benchmark is formulated. It allocates a class (reference type) for each
row. And allocating a million of such in a very short time favors a GC tuned for
high throughput (Server GC) over low latency (Workstation GC). Comparing to
CsvHelper:
- Workstation GC: Sep is 4.7x faster than CsvHelper
- Server GC: Sep is 11.5x faster than CsvHelper
An unfair comparison given multi-threaded vs single-threaded, but even for single-threaded Sep is 2-3x faster than CsvHelper. Sep is also faster than all other parsers, but for single-threaded only by a small margin to Sylvan.Data.Csv.
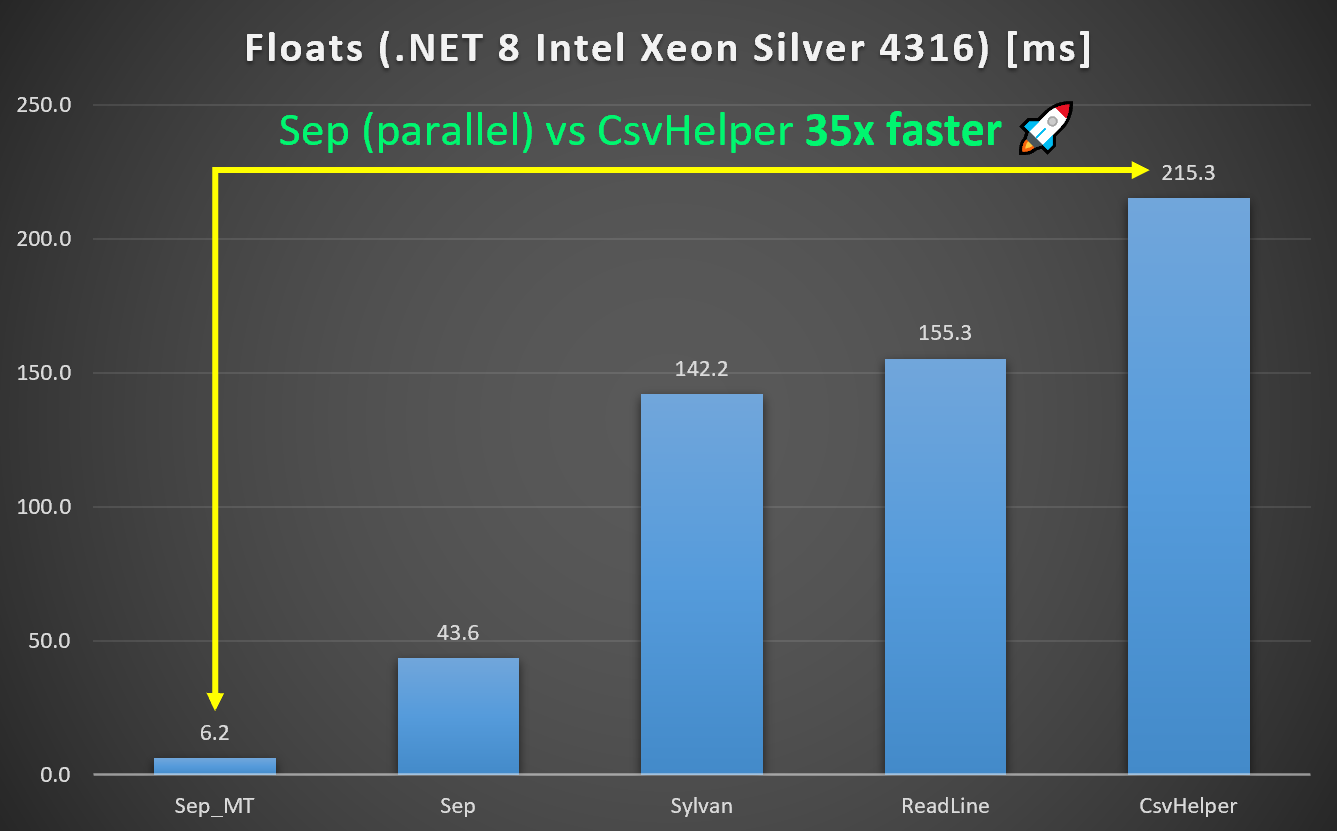
Floats Benchmark - Sep 35x Faster than CsvHelper
In the Sep repository there is a benchmark that compares floats
parsing
for Sep, CsvHelper, Sylvan.Data.Csv and a naive ReadLine implementation.
Parsing floats is a key usage scenario and the benchmark is used as a daily
driver in the development of Sep. With multi-threading support Sep is now up to
35x faster than CsvHelper on an Intel Xeon Silver 4316 with AVX-512 and
almost 5x faster single-threaded.
ParallelEnumerate Implementation
To fascillate efficient multi-threading support parsing internally in Sep had to be rewritten. Recall that if a csv-file contains quotes one has to parse the contents in sequence since there is no way of knowing when or where quotes will start or stop. In principle the first character in a file can be a quote and the last, which would make the entire contents of the file a single column row.
Hence, parallization is done after parsing the structure of chunks of input text. To do this efficiently and with no allocations state related to each chunk is reused. After that code for parallization is fairly simple and looks something like:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
var statesStack = new ConcurrentStack<SepReaderState>();
try
{
var states = EnumerateStates(reader, statesStack);
var statesParallel = states.AsParallel().AsOrdered();
var batches = statesParallel.Select(PooledSelect);
foreach (var batch in batches)
{
var (results, count) = batch;
for (var i = 0; i < count; i++)
{
yield return results[i];
}
ArrayPool<T>.Shared.Return(results);
}
}
finally
{
DisposeStates(statesStack);
}
(T[] Array, int Count) PooledSelect(SepReaderState s)
{
var array = ArrayPool<T>.Shared.Rent(s._parsedRowsCount);
var index = 0;
while (s.MoveNextAlreadyParsed())
{
array[index] = select(new(s));
++index;
}
statesStack.Push(s);
return (array, index);
}
where select is the user provided parsing function as a delegate. By default
Sep always returns parsed results in order, hence the AsOrdered() call.
The main work to support the above was refactoring and rewriting the internals
of Sep to support a SepReaderState that can be reused and which does not
involve memory copies but only swapping of buffers so the parsing is as
efficient as possible.
That’s all for this time, be sure to check out Sep on GitHub and leave a ⭐ if you haven’t already.