Sep 0.11.0 - 9.5 GB/s CSV Parsing Using ARM NEON SIMD on Apple M1 🚀
Sep 0.11.0 was released June 12th,
2025 with a new parser
optimized specifically for ARM NEON
SIMD (called AdvSimd in .NET)
capable ARM64 CPUs like the Apple M1)
or the new Microsoft cloud Cobalt
100,
which is based on the ARM Neoverse
N2.
Both of these are available as free runners on GitHub and it is those virtual instances that are used for benchmarking Sep on ARM64, as I have no ARM64 hardware myself. It was the new availability of Cobalt 100 based GitHub runners that triggered me adding a new ARM NEON SIMD parser to Sep, as early benchmarks of this looked a bit “slow” compared to other CPUs.
Previously, Sep on ARM would use a cross-platform SIMD parser based on
Vector128, which has been the case since early Sep e.g. Sep 0.2.0. Now Sep hits 9.5 GB/s on Apple M1 up
from ~7 GB/s with the cross-platform SIMD parser, and ~6 GB/s on Cobalt 100 up
from ~4 GB/s.
As seen last in Sep 0.10.0 - 21 GB/s CSV Parsing Using SIMD on AMD 9950X 🚀 this is not too bad compared to the insane performance of a large Zen 5 desktop core. I wonder what the performance would be on an Apple M4, but I do not have access to one. And it is pretty nice to be able to run such benchmarks as GitHub actions.
See v0.11.0 release for all changes for the release, and Sep README on GitHub for full details including detailed benchmarks.
Below I will dive into the new NEON SIMD parser, showing interesting code and assembly along the way. First I’ll show how low-level parsing performance of Sep has improved on Apple M1 due to this and how it compares to CsvHelper and Sylvan.Data.Csv.
Sep Performance on Apple M1
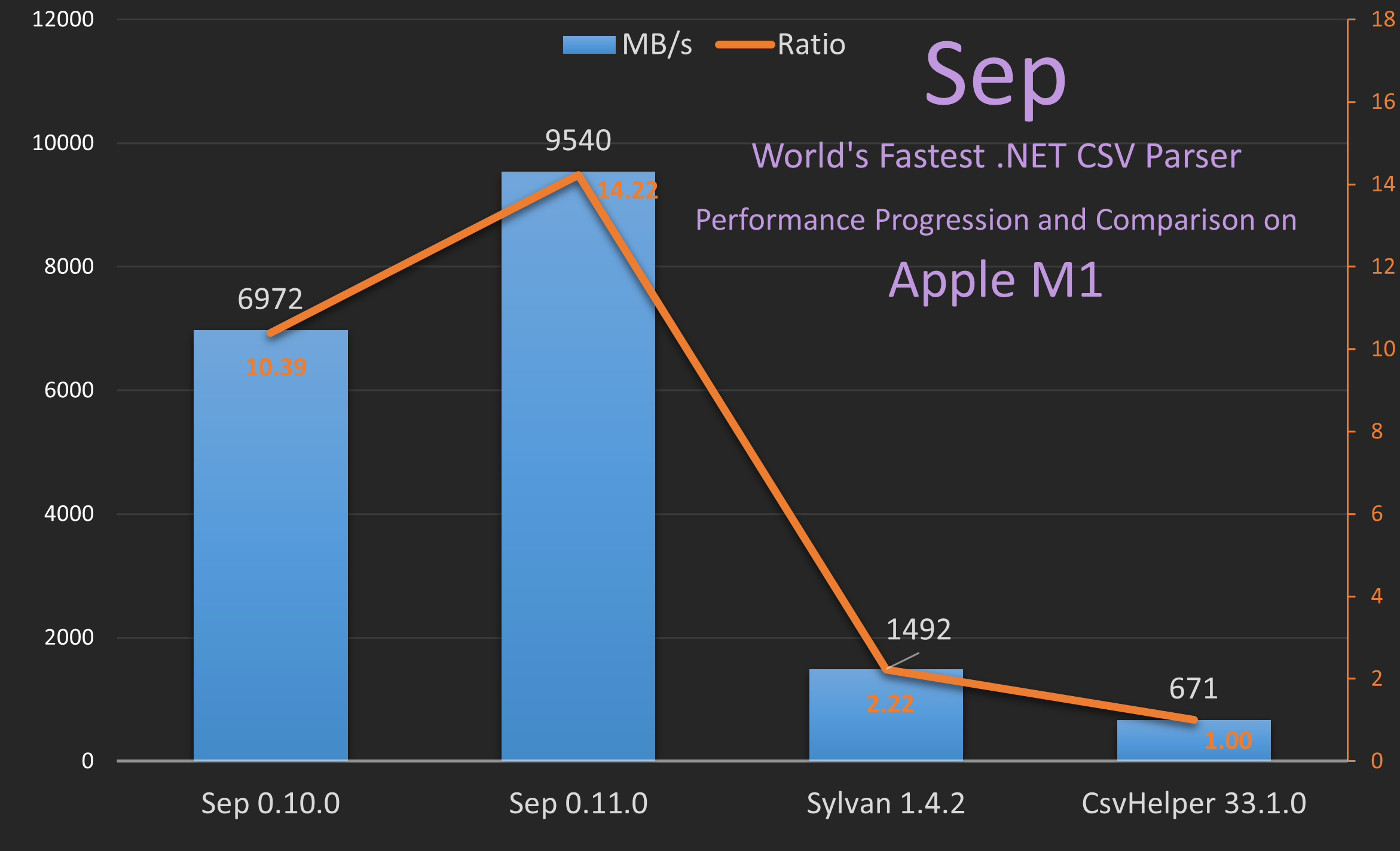
The above graph shows how Sep 0.11.0 improves the already stellar performance on Apple M1 compared to Sylvan and CsvHelper. Sep is now ~14x faster than CsvHelper at 9.5 GB/s vs 0.7 GB/s and 6.4x faster than Sylvan.
These numbers are, as seen before, for the package assets CSV data and the low
level parse Rows only scope, see Sep README on
GitHub or code on GitHub for details on this,
but to recap for new readers:
- 1 char = 2 bytes
- Based on
StringReaderandstringin memory to rule out any IO variation - Data intentionally small and typically fits in L3 cache to be able to measure impact of even small code changes
- Single-threaded
- No quotes, no trimming, no unescaping, but still real-world CSV
- Just CSV parsing only, rows only
- Warm runs only as per usual with
BenchmarkDotNet
In addition, since these benchmarks run on a virtual machine in the form of actions on a GitHub runner, there is higher variance. Usually locally I’d say there is about 5% variance but for GitHub runners this is about 10%, sometimes even much larger.
Hence, before Sep 0.11.0 using the cross-platform SIMD based parser on Apple M1 I’ve observed performance ranging from ~7000 - 7600 MB/s. With 0.11.0 and the NEON SIMD based parser this increases to ~8500-9700 MB/s, so the new parser is about 1.3-1.4x faster on Apple M1.
Sep Performance on Cobalt 100
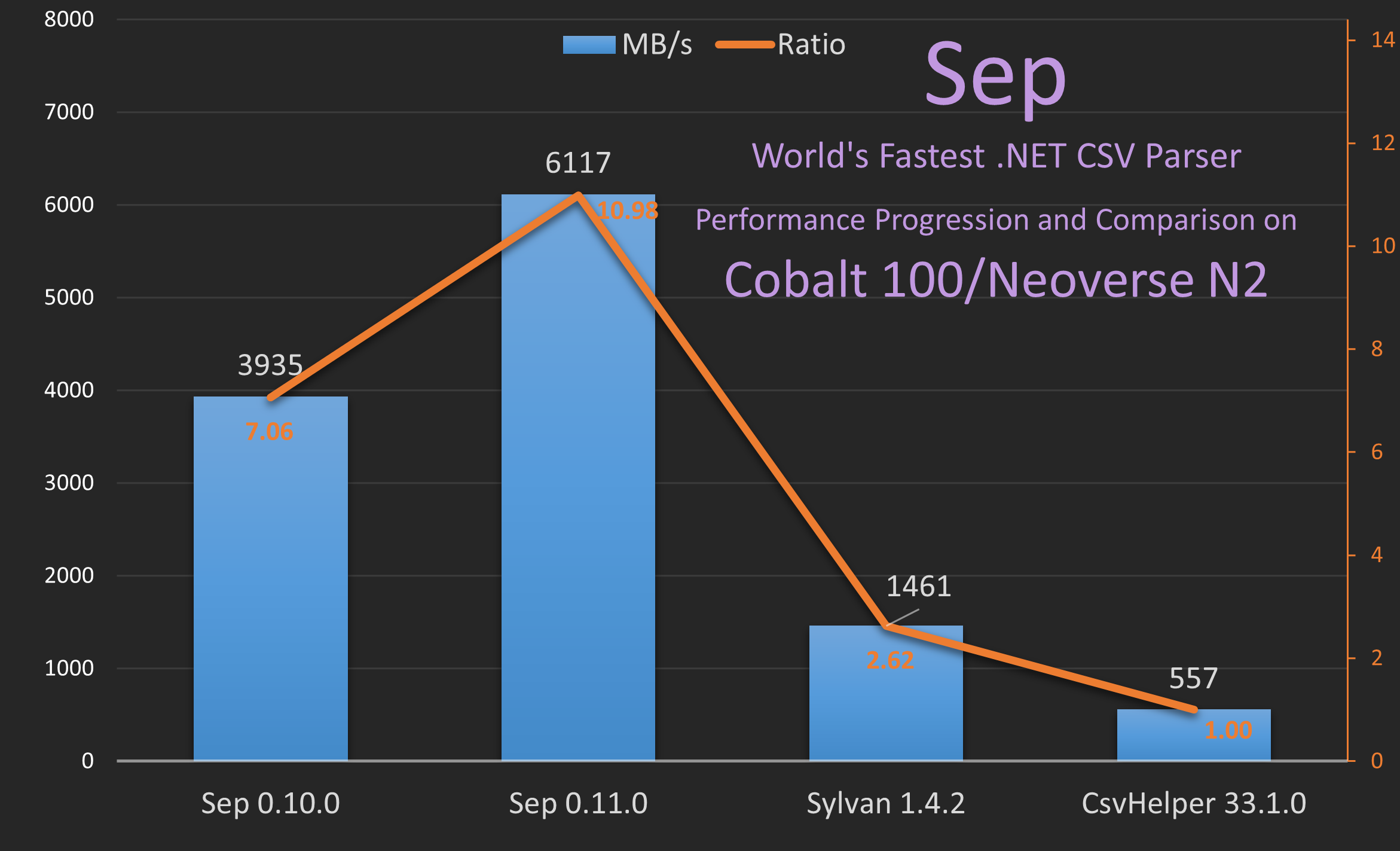
The performance on Cobalt 100 before Sep 0.11.0 was only ~4 GB/s, which is what triggered me looking into improving ARM performance, since this seemed rather slow. After Sep 0.11.0 this has improved to ~6 GB/s, which is a nice 1.5x improvement. Still fairly slow compared to “performance” cores, but these ARM cores are not really designed for maximum single-threaded performance, but rather for high efficiency and density.
As can be also seen compared to Sylvan and CsvHelper, Sep is now ~11x faster than CsvHelper at 6.1 GB/s vs 0.6 GB/s and 4.2x faster than Sylvan on ARM Neoverse N2.
Disassembling via dotnet publish and dumpbin on Windows
Not having any ARM64 PC myself also meant adding a specific parser for this presented new challenges, as I could neither test/debug the code directly nor inspect the assembly for it directly using Disasmo as usual (maybe that is possible but I do not know how). Debugging wasn’t that much of an issue, since I only had to do minor changes to SIMD code in 0.11.0 and few issues arose, but inspecting the assembly was more important to be sure the generated machine code was in line with expected instructions.
Now I could have tried using a GitHub action on e.g. Apple M1 runner to get to the assembly, but that would have been a terrible dev loop and I am too impatient for that.
Instead, I figured out I could use NativeAOT via dotnet publish of a small
test executable and have this generate an executable for win-arm64, which is
possible on Windows if you have the right development tools
installed
e.g. “Visual Studio 2022, including the Desktop development with C++ workload
with all default components.” And then I could use dumpbin to disassemble the
resulting executable as shown in the script below.
1
2
3
4
5
6
7
8
9
param(
[string]$runtime = "win-arm64"
)
dotnet publish src/Sep.Tester/Sep.Tester.csproj `
-c Release -r "$runtime" -f net9.0 --self-contained true `
/p:PublishAot=true /p:DebugSymbols=true
dumpbin /DISASM /SYMBOLS `
"artifacts\publish\Sep.Tester\release_net9.0_$runtime\Sep.Tester.exe" >`
"artifacts\publish\Sep.Tester\release_net9.0_$runtime\disassembly.asm"
The disassembly.asm file is then a text file that I can keep open in VS or
WinMerge and in which I manually search for relevant class names and methods,
which are available since there are debug symbols, to find the assembly I am
interested in. This also allows me to compare x64 vs ARM64 if need be.
Note that there may be differences in the assembly generated with NativeAOT vs JIT in general, but for the specific places where I am interested in this for Sep there hasn’t been any.
ARM SIMD - Cross-platform vs AdvSimd
Let’s take a look at the cross-platform SIMD C# code previously used on ARM (and
any other non-x86 platform with Vector128 hardware acceleration). Basic
approach has been discussed before also in Sep 0.10.0 blog post and I am showing only partial inner loop
code. For full code go to nietras/Sep on
GitHub.
Since cross-platform Vector128 SIMD does not (currently) have support for
saturated conversion/narrowing of 16-bit unsigned integers (e.g. char) to
8-bit unsigned integers (this is coming in .NET 10 I believe with
NarrowWithSaturation
methods), this is done by using
Min before Narrow as can be seen in the C# code below. Additionally, this
uses ExtractMostSignificantBits for MoveMask.
SepParserVector128NrwCmpExtMsbTzcnt
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
ref var charsRef = ref Add(ref charsOriginRef, (uint)charsIndex);
ref var byteRef = ref As<char, byte>(ref charsRef);
var v0 = ReadUnaligned<VecUI16>(ref byteRef);
var v1 = ReadUnaligned<VecUI16>(ref Add(ref byteRef, VecUI8.Count));
var limit0 = Vec.Min(v0, max);
var limit1 = Vec.Min(v1, max);
var bytes = Vec.Narrow(limit0, limit1);
var nlsEq = Vec.Equals(bytes, nls);
var crsEq = Vec.Equals(bytes, crs);
var qtsEq = Vec.Equals(bytes, qts);
var spsEq = Vec.Equals(bytes, sps);
var lineEndings = nlsEq | crsEq;
var lineEndingsSeparators = spsEq | lineEndings;
var specialChars = lineEndingsSeparators | qtsEq;
// Optimize for the case of no special character
var specialCharMask = MoveMask(specialChars);
if (specialCharMask != 0u)
The assembly for this, based on using NativeAOT and dumpbin as discussed above
for ARM64 with NEON SIMD support, is shown below. What is interesting here is
both the instructions needed for narrowing but also the many instructions needed
for the MoveMask operation, as ARM NEON does not have an equivalent to this
built-in. A clear oversight by ARM…
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
AD405935 ldp q21,q22,[x9]
6E706EB5 umin v21.8h,v21.8h,v16.8h
0E212AB5 xtn v21.8b,v21.8h
6E706ED6 umin v22.8h,v22.8h,v16.8h
4E212AD5 xtn2 v21.16b,v22.8h
6E318EB6 cmeq v22.16b,v21.16b,v17.16b
6E328EB7 cmeq v23.16b,v21.16b,v18.16b
6E338EB8 cmeq v24.16b,v21.16b,v19.16b
6E348EB5 cmeq v21.16b,v21.16b,v20.16b
4EB71ED6 orr v22.16b,v22.16b,v23.16b
4EB61EB6 orr v22.16b,v21.16b,v22.16b
4EB81ED7 orr v23.16b,v22.16b,v24.16b
4F04E418 movi v24.16b,#0x80
4E381EF7 and v23.16b,v23.16b,v24.16b
9C0019F9 ldr q25,000000014007B140
6E3946F7 ushl v23.16b,v23.16b,v25.16b
4EB71EFA mov v26.16b,v23.16b
0E31BB5A addv b26,v26.8b
0E013F4D umov w13,v26.b[0]
6E1742F7 ext8 v23.16b,v23.16b,v23.16b,#8
0E31BAF7 addv b23,v23.8b
0E013EEE umov w14,v23.b[0]
2A0E21AD orr w13,w13,w14,lsl #8
2A0D03ED mov w13,w13
B4FFFC4D cbz x13,000000014007ADB4
Many people have noticed this and in Links below I have listed a few resources that discuss this. One of which is Fitting My Head Through The ARM Holes or: Two Sequences to Substitute for the Missing PMOVMSKB Instruction on ARM NEON by Geoff Langdale, a notable figure in the SIMD community and one of the authors on the sadly incomplete simdcsv. The blog post discusses a way to do “move mask” efficiently in bulk for four 128-bit registers in one go. Please read that blog post for more, since I won’t cover the trickery here 😊.
This is the approach I have added in
SepParserAdvSimdNrwCmpOrBulkMoveMaskTzcnt, with key code shown below, in
addition to using efficient saturated conversion from 16-bit to 8-bit, which is
supported in ARM NEON. However, to do that here we have to load a total of 8 x
Vector128s in each loop first, and then narrow/convert to 4 x Vector128,
before doing comparisons, or’ing and finally extract bits to get a mask. This
means this parser is handling 1024 bits or 64 x chars at a time, which is the
same as the AVX-512 based parser. And the logic is based on comparisons
resulting in all bits being 1 for each byte where the comparison is equal.
SepParserAdvSimdNrwCmpOrBulkMoveMaskTzcnt
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
ref var charsRef = ref Add(ref charsOriginRef, (uint)charsIndex);
var bytes0 = ReadNarrow(ref charsRef);
var bytes1 = ReadNarrow(ref Add(ref charsRef, VecUI8.Count * 1));
var bytes2 = ReadNarrow(ref Add(ref charsRef, VecUI8.Count * 2));
var bytes3 = ReadNarrow(ref Add(ref charsRef, VecUI8.Count * 3));
var nlsEq0 = AdvSimd.CompareEqual(bytes0, nls);
var crsEq0 = AdvSimd.CompareEqual(bytes0, crs);
var qtsEq0 = AdvSimd.CompareEqual(bytes0, qts);
var spsEq0 = AdvSimd.CompareEqual(bytes0, sps);
var lineEndings0 = AdvSimd.Or(nlsEq0, crsEq0);
var lineEndingsSeparators0 = AdvSimd.Or(spsEq0, lineEndings0);
var specialChars0 = AdvSimd.Or(lineEndingsSeparators0, qtsEq0);
var nlsEq1 = AdvSimd.CompareEqual(bytes1, nls);
var crsEq1 = AdvSimd.CompareEqual(bytes1, crs);
var qtsEq1 = AdvSimd.CompareEqual(bytes1, qts);
var spsEq1 = AdvSimd.CompareEqual(bytes1, sps);
var lineEndings1 = AdvSimd.Or(nlsEq1, crsEq1);
var lineEndingsSeparators1 = AdvSimd.Or(spsEq1, lineEndings1);
var specialChars1 = AdvSimd.Or(lineEndingsSeparators1, qtsEq1);
var nlsEq2 = AdvSimd.CompareEqual(bytes2, nls);
var crsEq2 = AdvSimd.CompareEqual(bytes2, crs);
var qtsEq2 = AdvSimd.CompareEqual(bytes2, qts);
var spsEq2 = AdvSimd.CompareEqual(bytes2, sps);
var lineEndings2 = AdvSimd.Or(nlsEq2, crsEq2);
var lineEndingsSeparators2 = AdvSimd.Or(spsEq2, lineEndings2);
var specialChars2 = AdvSimd.Or(lineEndingsSeparators2, qtsEq2);
var nlsEq3 = AdvSimd.CompareEqual(bytes3, nls);
var crsEq3 = AdvSimd.CompareEqual(bytes3, crs);
var qtsEq3 = AdvSimd.CompareEqual(bytes3, qts);
var spsEq3 = AdvSimd.CompareEqual(bytes3, sps);
var lineEndings3 = AdvSimd.Or(nlsEq3, crsEq3);
var lineEndingsSeparators3 = AdvSimd.Or(spsEq3, lineEndings3);
var specialChars3 = AdvSimd.Or(lineEndingsSeparators3, qtsEq3);
// Optimize for the case of no special character
var specialCharMask = MoveMask(specialChars0, specialChars1,
specialChars2, specialChars3);
if (specialCharMask != 0u)
1
2
3
4
5
6
7
8
9
10
11
[MethodImpl(MethodImplOptions.AggressiveInlining)]
static VecUI8 ReadNarrow(ref char charsRef)
{
ref var byteRef = ref As<char, byte>(ref charsRef);
var v0 = ReadUnaligned<VecUI16>(ref byteRef);
var v1 = ReadUnaligned<VecUI16>(ref Add(ref byteRef, VecUI8.Count));
var r0 = AdvSimd.ExtractNarrowingSaturateLower(v0);
var r1 = AdvSimd.ExtractNarrowingSaturateUpper(r0, v1);
return r1;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
[MethodImpl(MethodImplOptions.AggressiveInlining)]
internal static nuint MoveMask(VecUI8 p0, VecUI8 p1, VecUI8 p2, VecUI8 p3)
{
var bitmask = Vec.Create(
0x01, 0x02, 0x04, 0x08, 0x10, 0x20, 0x40, 0x80,
0x01, 0x02, 0x04, 0x08, 0x10, 0x20, 0x40, 0x80
);
var t0 = AdvSimd.And(p0, bitmask);
var t1 = AdvSimd.And(p1, bitmask);
var t2 = AdvSimd.And(p2, bitmask);
var t3 = AdvSimd.And(p3, bitmask);
var sum0 = AdvSimd.Arm64.AddPairwise(t0, t1);
var sum1 = AdvSimd.Arm64.AddPairwise(t2, t3);
sum0 = AdvSimd.Arm64.AddPairwise(sum0, sum1);
sum0 = AdvSimd.Arm64.AddPairwise(sum0, sum0);
return (nuint)sum0.AsUInt64().GetElement(0);
}
The assembly for this can be seen below. Given this now processes a lot more in one go there are a lot more repeated instructions, but then we also reduce the relative number of instructions per bit in the mask generated since we handle more at a time. The performance benefits are clear given the numbers shown above. All thanks to Geoff Langdale 🙏
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
AD405534 ldp q20,q21,[x9]
2E214A94 uqxtn v20.8b,v20.8h
6E214AB4 uqxtn2 v20.16b,v21.8h
9100812D add x13,x9,#0x20
AD4059B5 ldp q21,q22,[x13]
2E214AB5 uqxtn v21.8b,v21.8h
6E214AD5 uqxtn2 v21.16b,v22.8h
9101012D add x13,x9,#0x40
AD405DB6 ldp q22,q23,[x13]
2E214AD6 uqxtn v22.8b,v22.8h
6E214AF6 uqxtn2 v22.16b,v23.8h
9101812D add x13,x9,#0x60
AD4061B7 ldp q23,q24,[x13]
2E214AF7 uqxtn v23.8b,v23.8h
6E214B17 uqxtn2 v23.16b,v24.8h
6E308E98 cmeq v24.16b,v20.16b,v16.16b
6E318E99 cmeq v25.16b,v20.16b,v17.16b
6E328E9A cmeq v26.16b,v20.16b,v18.16b
6E338E94 cmeq v20.16b,v20.16b,v19.16b
4EB91F18 orr v24.16b,v24.16b,v25.16b
4EB81E98 orr v24.16b,v20.16b,v24.16b
4EBA1F19 orr v25.16b,v24.16b,v26.16b
6E308EBA cmeq v26.16b,v21.16b,v16.16b
6E318EBB cmeq v27.16b,v21.16b,v17.16b
6E328EBC cmeq v28.16b,v21.16b,v18.16b
6E338EB5 cmeq v21.16b,v21.16b,v19.16b
4EBB1F5A orr v26.16b,v26.16b,v27.16b
4EBA1EBA orr v26.16b,v21.16b,v26.16b
4EBC1F5B orr v27.16b,v26.16b,v28.16b
6E308EDC cmeq v28.16b,v22.16b,v16.16b
6E318EDD cmeq v29.16b,v22.16b,v17.16b
6E328EDE cmeq v30.16b,v22.16b,v18.16b
6E338ED6 cmeq v22.16b,v22.16b,v19.16b
4EBD1F9C orr v28.16b,v28.16b,v29.16b
4EBC1EDC orr v28.16b,v22.16b,v28.16b
4EBE1F9D orr v29.16b,v28.16b,v30.16b
6E308EFE cmeq v30.16b,v23.16b,v16.16b
6E318EFF cmeq v31.16b,v23.16b,v17.16b
6E328EE7 cmeq v7.16b,v23.16b,v18.16b
6E338EF7 cmeq v23.16b,v23.16b,v19.16b
4EBF1FDE orr v30.16b,v30.16b,v31.16b
4EBE1EFE orr v30.16b,v23.16b,v30.16b
4EA71FDF orr v31.16b,v30.16b,v7.16b
9C0019E7 ldr q7,000000014007AD30
4E271F39 and v25.16b,v25.16b,v7.16b
4E271F7B and v27.16b,v27.16b,v7.16b
4E3BBF39 addp v25.16b,v25.16b,v27.16b
4E271FBB and v27.16b,v29.16b,v7.16b
4E271FFD and v29.16b,v31.16b,v7.16b
4E3DBF7B addp v27.16b,v27.16b,v29.16b
4E3BBF39 addp v25.16b,v25.16b,v27.16b
4E39BF39 addp v25.16b,v25.16b,v25.16b
4E083F2D mov x13,v25.d[0]
B4FFF8AD cbz x13,000000014007A930
Links
Interesting links related to ARM SIMD. The first one explains the approach adopted by Sep for efficient bulk move mask in ARM NEON. Others, can be used for inspiration or perhaps future improvements to Sep.
- Fitting My Head Through The ARM Holes or: Two Sequences to Substitute for the Missing PMOVMSKB Instruction on ARM NEON by Geoff Langdale.
- Pruning Spaces Faster on ARM Processors with Vector Table Lookups by Daniel Lemire.
- Bit twiddling with Arm Neon: beating SSE movemasks, counting bits and more by Danila Kutenin.
- ARM Intrinsics
That’s all!