Sep 0.10.0 - 21 GB/s CSV Parsing Using SIMD on AMD 9950X 🚀
Sep 0.10.0 was released April 22nd, 2025 with optimizations for AVX-512 capable CPUs like the AMD 9950X (Zen 5) and updated benchmarks including the 9950X. Sep now achieves a staggering 21 GB/s on the 9950X for the low-level CSV parsing. 🚀 Before 0.10.0, Sep achieved ~18 GB/s on 9950X.
See v0.10.0 release for all changes for the release, and Sep README on GitHub for full details.
In this blog post, I will dive into how .NET 9.0 machine code for AVX-512 is sub-optimal and what changes were made to speed up Sep for AVX-512 by circumventing this, showing interesting code and assembly along the way, so get ready for SIMD C# code, x64 SIMD assembly and tons of benchmark numbers.
However, first let’s take a look at the progression of Sep’s performance from early 0.1.0 to 0.10.0, from .NET 7.0 to .NET 9.0 and from AMD Ryzen 9 5950X (Zen 3) to 9950X (Zen 5), as I have also recently upgraded my work PC.
Sep Performance Progression
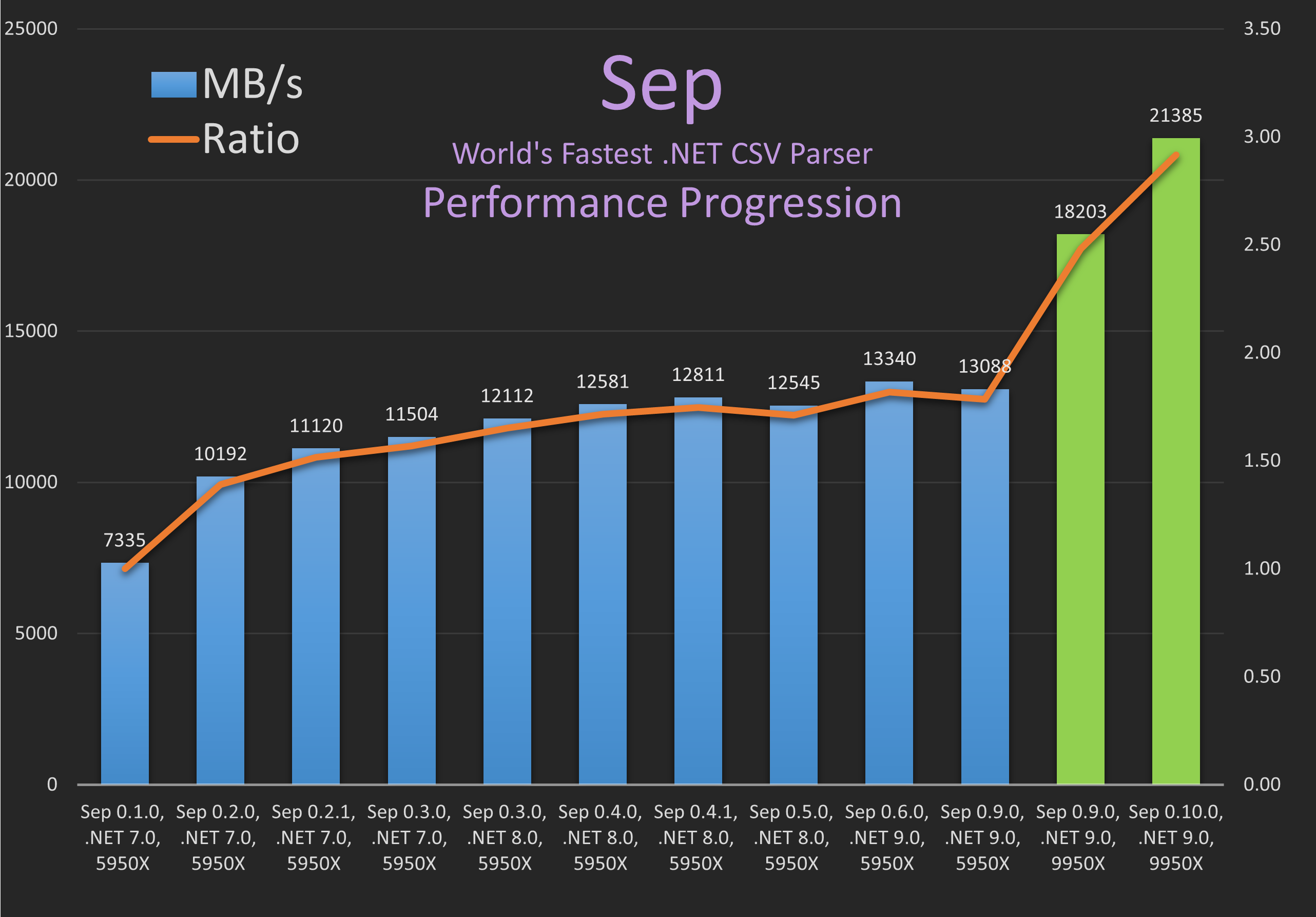
The benchmark numbers above are for the package assets CSV data and the low
level parse Rows only scope, see Sep README on
GitHub or code on GitHub for details on this.
Note that all numbers here are single-threaded and are also shown in the table
below. Note that there can be a few percentage points variation in the numbers,
so for a given release Sep might see minor regressions.
The main take away is that Sep has seen incremental improvements to performance driven by both major (e.g. almost complete rewrite of internals in 0.2.0) and minor code changes. While also seeing improved performance on new .NET versions. And finally here showing improvement for going from the AMD 5950X (Zen 3) to AMD 9950X (Zen 5). Hence, this showcases how software together with hardware improvements can boost performance to the next level.
We can see Sep progressing:
~ 7 GB/s(0.1.0, 5950X and .NET 7.0)~12 GB/s(0.3.0, 5950X and .NET 8.0)~13 GB/s(0.6.0, 5950X and .NET 9.0)~18 GB/s(0.9.0, 9950X and .NET 9.0)~21 GB/s(0.10.0, 9950X and .NET 9.0)
This is a staggering ~3x improvement in just under 2 years since Sep was introduced June, 2023.
| Sep | .NET | CPU | Rows | Mean [ms] | MB | MB/s | Ratio | ns/row |
|---|---|---|---|---|---|---|---|---|
| 0.1.0 | 7.0 | 5950X | 1000000 | 79.590 | 583 | 7335.3 |
1.00 | 79.6 |
| 0.2.0 | 7.0 | 5950X | 1000000 | 57.280 | 583 | 10191.6 |
1.39 | 57.3 |
| 0.2.1 | 7.0 | 5950X | 50000 | 2.624 | 29 | 11120.2 |
1.52 | 52.5 |
| 0.3.0 | 7.0 | 5950X | 50000 | 2.537 | 29 | 11503.7 |
1.57 | 50.7 |
| 0.3.0 | 8.0 | 5950X | 50000 | 2.409 | 29 | 12111.6 |
1.65 | 48.2 |
| 0.4.0 | 8.0 | 5950X | 50000 | 2.319 | 29 | 12581.3 |
1.72 | 46.4 |
| 0.4.1 | 8.0 | 5950X | 50000 | 2.278 | 29 | 12811.2 |
1.75 | 45.6 |
| 0.5.0 | 8.0 | 5950X | 50000 | 2.326 | 29 | 12544.5 |
1.71 | 46.5 |
| 0.6.0 | 9.0 | 5950X | 50000 | 2.188 | 29 | 13339.9 |
1.82 | 43.8 |
| 0.9.0 | 9.0 | 5950X | 50000 | 2.230 | 29 | 13088.4 |
1.78 | 44.6 |
| 0.9.0 | 9.0 | 9950X | 50000 | 1.603 | 29 | 18202.7 |
2.48 | 32.1 |
| 0.10.0 | 9.0 | 9950X | 50000 | 1.365 | 29 | 21384.9 |
2.92 | 27.3 |
The improvement from 5950X w. Sep 0.9.0 to 9950X w. Sep 0.10.0 is ~1.6x
which is a pretty good improvement from Zen 3 to Zen 5. Note the 9950X has a 5.7
GHz boost frequency vs 4.9 GHz for 5950X, so this alone probably explains 1.2x.
AVX-512 Code Generation and Mask Register Issues
Sep has had support for AVX-512 since 0.2.3 and back then I noted that:
different here is the use of the mask registers (
k1-k8) introduced with AVX-512. However, .NET 8 does not have explicit support for these and the code generation is a bit suboptimal, given mask register are moved to normal registers each time. And then back.
I did not have direct access to an AVX-512 capable CPU then, so I could not test the performance of the AVX-512 in detail, but did verify it on the Xeon Silver 4316 which based on some quick tests showed the AVX-512 parser to be the fastest on that CPU despite the issues with the mask registers.
9950X Upgrade and AVX-512 vs AVX2 Performance
Recently, I then upgraded from an AMD 5950X (Zen 3) CPU to an AMD 9950X (Zen 5) CPU. Zen 3 does not support AVX-512, but Zen 5 does. One of the first things I did on the new CPU was of course to run the Sep benchmarks, and this showed, that Sep hit ~18 GB/s on the 9950X for the low-level parsing of CSV files. This was great and ~1.4x faster than on the 5950X. A pretty good improvement from Zen 3 to Zen 5.
However, I still wanted to compare AVX-512 to AVX2. Sep has, unofficial, support for overriding the default selected parser via an environment variable. This is also used for testing all possible parsers fully no matter which parser is selected as best. A bit surprisingly the AVX2 parser on 9950X hit ~20GB/s! That is, it was better than the AVX-512 based parser by ~10%, which is pretty significant for Sep. Hence, it would seem the mask register issue was still an issue.
Parser Code/Assembly Comparison and New AVX-512-to-256 Parser
Let’s examine the code and assembly (via Disasmo) for the AVX-512-based parser (0.9.0), a tweaked version (0.10.0), compare it to the AVX2-based parser, and finally review a new AVX-512-to-256-based parser that circumvents the mask register issue and is even faster than the AVX2-based parser, achieving ~21 GB/s as shown above.
Parse Methods
All parsers in Sep follow the same basic layout as shown below and have a single
generic Parse method to support both parsing for when handling quotes
(ParseColInfos) and when not (ParseColEnds). The former requires keeping
track of more state, and is slightly slower.
In Sep the Parse method is marked with AggressiveInlining to ensure it is
inlined, which means one can in principle go to ParseColEnds in Visual Studio
with Disasmo installed and hit ALT + SHIFT + D. Unfortunately, for some reason
this does not work currently unless you change the parser from a class to
struct. So readers are aware if they want to follow along. See GitHub issue
Empty disassembly for method with inlined generic method (used to
work) for more.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public void ParseColEnds(SepReaderState s)
{
Parse<int, SepColEndMethods>(s);
}
public void ParseColInfos(SepReaderState s)
{
Parse<SepColInfo, SepColInfoMethods>(s);
}
void Parse<TColInfo, TColInfoMethods>(SepReaderState s)
where TColInfo : unmanaged
where TColInfoMethods : ISepColInfoMethods<TColInfo>
{
// Implementation
}
To recap, parsing in Sep is done on a span of chars (from an array) e.g. 16K
and outputs a set of column end indices and row column counts for that span.
This ensures parsing is done on a significant yet small enough chunk of data to
fit in the CPU cache, and facilitates efficient multi-threading after too.
Parsing of the span is basically then just a loop where one or two SIMD
registers (e.g. Vector256) are loaded (as unsigned 16-bit integers e.g.
ushort) and converted to byte SIMD register and then compared to the special
characters (e.g. \n, \r, ", ;) using SIMD compare instructions. The
compare results are then converted to bit masks and each set bit in that mask is
sequentially parsed after.
The interesting part here is the SIMD code and how it’s JIT’ed to machine code on .NET and how efficient that is. Below this specific code and assembly is shown for the parsers mentioned before.
SepParserAvx512PackCmpOrMoveMaskTzcnt.cs (0.9.0)
A breakdown of the below code snippet:
- Data Loading and Packing:
- Two 16-bit integer vectors (
v0andv1) are read from memory using unaligned reads. - These vectors are packed into a single byte vector using
PackUnsignedSaturate, ensuring values fit within the byte range. - For AVX-512 this means loading two 512-bit SIMD registers each with
32
chars and then packing it to single 512-bit SIMD register with 64 bytes. This means 64chars are handled in each loop.
- Two 16-bit integer vectors (
- Reordering Packed Data:
- The packed data is interleaved, so a permutation operation
(
PermuteVar8x64) is applied to reorder the bytes into the correct sequence.
- The packed data is interleaved, so a permutation operation
(
- Character Comparisons:
- The byte vector is compared against specific characters (e.g.
\n,\r,",;) using SIMD equality operations. These comparisons identify special characters relevant to CSV parsing.
- The byte vector is compared against specific characters (e.g.
- Combine Comparison Results:
- The results of the comparisons are combined using logical operations.
- Bitmask Generation and Check:
- A
MoveMaskoperation extracts a bitmask from the SIMD register, allowing for a quick check to skip further processing if no special characters are found.
- A
All parsers follow the same basic approach, so this description will be omitted
going forward. Note how ISA and Vec are aliases used to make the different
parsers more similar which makes it easier to compare and maintain the different
parsers.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
var v0 = ReadUnaligned<VecI16>(ref byteRef);
var v1 = ReadUnaligned<VecI16>(ref Add(ref byteRef, VecUI8.Count));
var packed = ISA.PackUnsignedSaturate(v0, v1);
// Pack interleaves the two vectors need to permute them back
var permuteIndices = Vec.Create(0L, 2L, 4L, 6L, 1L, 3L, 5L, 7L);
var bytes = ISA.PermuteVar8x64(packed.AsInt64(), permuteIndices).AsByte();
var nlsEq = Vec.Equals(bytes, nls);
var crsEq = Vec.Equals(bytes, crs);
var qtsEq = Vec.Equals(bytes, qts);
var spsEq = Vec.Equals(bytes, sps);
var lineEndings = nlsEq | crsEq;
var lineEndingsSeparators = spsEq | lineEndings;
var specialChars = lineEndingsSeparators | qtsEq;
// Optimize for the case of no special character
var specialCharMask = MoveMask(specialChars);
if (specialCharMask != 0u)
Assembly is shown below for a 64-bit CPU with AVX-512 support e.g. the 9950X.
What is most interesting here is that each compare Vec.Equals ends up being
two instructions vpcmpeqb (compare equal bytes) and vpmovm2b
(move mask to byte). That is, there is a lot of going from the mask
register, e.g. k1, to a normal 512-bit register, e.g. zmm5, and back again.
Note that the C# code does not deal with vector mask registers directly. This is not supported in .NET and hence it is the JIT that is responsible for code generation around this. Unfortunately, here it does not do a good job and the AVX-512 is not as fast as it could be.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
mov edi, r9d
lea rdi, bword ptr [r10+2*rdi]
vmovups zmm4, zmmword ptr [rdi]
vpackuswb zmm4, zmm4, zmmword ptr [rdi+0x40]
vmovups zmm5, zmmword ptr [reloc @RWD00]
vpermq zmm4, zmm5, zmm4
vpcmpeqb k1, zmm4, zmm0
vpmovm2b zmm5, k1
vpcmpeqb k1, zmm4, zmm1
vpmovm2b zmm16, k1
vpcmpeqb k1, zmm4, zmm2
vpmovm2b zmm17, k1
vpcmpeqb k1, zmm4, zmm3
vpmovm2b zmm4, k1
vpternlogd zmm5, zmm4, zmm16, -2
vpord zmm16, zmm5, zmm17
vpmovb2m k1, zmm16
kmovq r15, k1
test r15, r15
je G_M000_IG03
vpmovb2m k1, zmm4
kmovq r13, k1
lea r12, [r15+r8]
cmp r13, r12
je G_M000_IG43
SepParserAvx512PackCmpOrMoveMaskTzcnt.cs (0.10.0)
To address the above code generation issues, in Sep 0.10.0 I changed the AVX-512
based parser by moving the MoveMask calls earlier to avoid the whole mask
register back and forth as shown below. For other parsers, MoveMask is only
called when necessary to reduce instructions in the “happy”/skip path.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
var v0 = ReadUnaligned<VecI16>(ref byteRef);
var v1 = ReadUnaligned<VecI16>(ref Add(ref byteRef, VecUI8.Count));
var packed = ISA.PackUnsignedSaturate(v0, v1);
// Pack interleaves the two vectors need to permute them back
var permuteIndices = Vec.Create(0L, 2L, 4L, 6L, 1L, 3L, 5L, 7L);
var bytes = ISA.PermuteVar8x64(packed.AsInt64(), permuteIndices).AsByte();
var nlsEq = MoveMask(Vec.Equals(bytes, nls));
var crsEq = MoveMask(Vec.Equals(bytes, crs));
var qtsEq = MoveMask(Vec.Equals(bytes, qts));
var spsEq = MoveMask(Vec.Equals(bytes, sps));
var lineEndings = nlsEq | crsEq;
var lineEndingsSeparators = spsEq | lineEndings;
var specialChars = lineEndingsSeparators | qtsEq;
// Optimize for the case of no special character
var specialCharMask = specialChars;
if (specialCharMask != 0u)
This improves the assembly for the parser quite a bit as can be seen below. Basically, less instructions. We are still going to mask register to normal register but at least only once.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
mov edi, r9d
lea rdi, bword ptr [r10+2*rdi]
vmovups zmm4, zmmword ptr [rdi]
vpackuswb zmm4, zmm4, zmmword ptr [rdi+0x40]
vmovups zmm5, zmmword ptr [reloc @RWD00]
vpermq zmm4, zmm5, zmm4
vpcmpeqb k1, zmm4, zmm0
kmovq r15, k1
vpcmpeqb k1, zmm4, zmm1
kmovq r13, k1
vpcmpeqb k1, zmm4, zmm2
kmovq r12, k1
vpcmpeqb k1, zmm4, zmm3
kmovq rcx, k1
or r15, rcx
or r15, r13
or r12, r15
je SHORT G_M000_IG03
mov r13, rcx
lea rcx, [r12+r8]
cmp r13, rcx
je G_M000_IG43
SepParserAvx2PackCmpOrMoveMaskTzcnt.cs (0.10.0)
Let’s compare the AVX-512 to the AVX2 based parser. C# code is shown below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
var v0 = ReadUnaligned<VecI16>(ref byteRef);
var v1 = ReadUnaligned<VecI16>(ref Add(ref byteRef, VecUI8.Count));
var packed = ISA.PackUnsignedSaturate(v0, v1);
// Pack interleaves the two vectors need to permute them back
var bytes = ISA.Permute4x64(packed.AsInt64(), 0b_11_01_10_00).AsByte();
var nlsEq = Vec.Equals(bytes, nls);
var crsEq = Vec.Equals(bytes, crs);
var qtsEq = Vec.Equals(bytes, qts);
var spsEq = Vec.Equals(bytes, sps);
var lineEndings = nlsEq | crsEq;
var lineEndingsSeparators = spsEq | lineEndings;
var specialChars = lineEndingsSeparators | qtsEq;
// Optimize for the case of no special character
var specialCharMask = MoveMask(specialChars);
if (specialCharMask != 0u)
The assembly below is, however, clearly more straightforward as there are no mask registers involved. This explains why the AVX2 based parser is faster than the old (0.9.0) AVX-512 based parser.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
mov edi, r9d
lea rdi, bword ptr [r10+2*rdi]
vmovups ymm4, ymmword ptr [rdi]
vpackuswb ymm4, ymm4, ymmword ptr [rdi+0x20]
vpermq ymm4, ymm4, -40
vpcmpeqb ymm5, ymm4, ymm0
vpcmpeqb ymm6, ymm4, ymm1
vpcmpeqb ymm7, ymm4, ymm2
vpcmpeqb ymm4, ymm4, ymm3
vpternlogd ymm5, ymm4, ymm6, -2
vpor ymm6, ymm5, ymm7
vpmovmskb r15d, ymm6
mov r15d, r15d
test r15, r15
je SHORT G_M000_IG03
vpmovmskb r13d, ymm4
mov r13d, r13d
lea r12, [r15+r8]
cmp r13, r12
je G_M000_IG43
SepParserAvx512To256CmpOrMoveMaskTzcnt.cs (0.10.0)
Given that even the tweaked AVX-512 (0.10.0) based parser had issues with mask
registers, I kept thinking that perhaps there was a more straightforward way to
do this, and then after some searching and unfruitful discussions with LLMs I
figured out that one could just use AVX-512 instructions for loading the chars
and then convert the 16-bit to 8-bit bytes saturated as a 256-bit register,
avoiding the 512-bit mask registers, by using
ConvertToVector256ByteWithSaturation (vpmovuswb) as shown below. This “only”
parses 32 chars at a time, but it is much simpler and avoids the mask register
issue.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
var v = ReadUnaligned<VecUI16>(ref byteRef);
var bytes = ISA.ConvertToVector256ByteWithSaturation(v);
var nlsEq = Vec.Equals(bytes, nls);
var crsEq = Vec.Equals(bytes, crs);
var qtsEq = Vec.Equals(bytes, qts);
var spsEq = Vec.Equals(bytes, sps);
var lineEndings = nlsEq | crsEq;
var lineEndingsSeparators = spsEq | lineEndings;
var specialChars = lineEndingsSeparators | qtsEq;
// Optimize for the case of no special character
var specialCharMask = MoveMask(specialChars);
if (specialCharMask != 0u)
The assembly then is much simpler and direct (closer to AVX2) and not only
avoids the mask register issues but also has more straightforward saturated
conversion since no permutation is needed as the packed data is already in order
just in the ymm4 register (that is the 256-bit part of zmm4).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
mov edi, r9d
lea rdi, bword ptr [r10+2*rdi]
vmovups zmm4, zmmword ptr [rdi]
vpmovuswb zmm4, zmm4
vpcmpeqb ymm5, ymm4, ymm0
vpcmpeqb ymm6, ymm4, ymm1
vpcmpeqb ymm7, ymm4, ymm2
vpcmpeqb ymm4, ymm4, ymm3
vpternlogd ymm5, ymm4, ymm6, -2
vpor ymm6, ymm5, ymm7
vpmovmskb r15d, ymm6
mov r15d, r15d
test r15, r15
je SHORT G_M000_IG03
vpmovmskb r13d, ymm4
mov r13d, r13d
lea r12, [r15+r8]
cmp r13, r12
je G_M000_IG43
And this is what brings Sep parsing up to a staggering 21 GB/s on the 9950X! 🚀
All Parsers Benchmarks
Finally, given all the parsers available in Sep I have added a benchmark, that uses the aforementioned environment variable, to run all parsers and compare their performance on the low level row parsing to better gauge their individual performance on the same CPU. Here the AMD 9950X.
The new AVX-512-to-256 parser is the fastest parser of all hitting ~21.5 GB/s,
but the Vector256/AVX2 based parsers are not far behind (about 5%).
SepParserVector256NrwCmpExtMsbTzcnt is the cross-platform Vector256 based
parser and it is notably now on par with the AVX2, but note how the other
cross-platform Vector128 and Vector512 based parsers are not (still fast but
5-10% slower), and even worse that the Vector512 one is slower than the
Vector128.
SepParserIndexOfAny is far behind, and should make it clear that any ideas
that this could be used to compete with Sep are not realistic. 😉 Vector64 is
not accelerated on the 9950X and therefore very slow. It’s just there for
completeness.
| Parser | MB/s | ns/row | Mean |
|---|---|---|---|
| SepParserAvx512To256CmpOrMoveMaskTzcnt | 21597.7 |
27.0 | 1.351 ms |
| SepParserVector256NrwCmpExtMsbTzcnt | 20608.5 |
28.3 | 1.416 ms |
| SepParserAvx2PackCmpOrMoveMaskTzcnt | 20599.3 |
28.3 | 1.417 ms |
| SepParserAvx512PackCmpOrMoveMaskTzcnt | 19944.3 |
29.3 | 1.463 ms |
| SepParserAvx256To128CmpOrMoveMaskTzcnt | 19465.5 |
30.0 | 1.499 ms |
| SepParserSse2PackCmpOrMoveMaskTzcnt | 19312.5 |
30.2 | 1.511 ms |
| SepParserVector128NrwCmpExtMsbTzcnt | 18252.1 |
32.0 | 1.599 ms |
| SepParserVector512NrwCmpExtMsbTzcnt | 18067.4 |
32.3 | 1.615 ms |
| SepParserIndexOfAny | 2787.0 |
209.4 | 10.471 ms |
| SepParserVector64NrwCmpExtMsbTzcnt | 459.9 |
1268.9 | 63.446 ms |
Top Level 5950X vs 9950X Benchmarks
Finally, the table below shows the top level benchmarks for the 5950X and 9950X CPUs for the package assets and floats data.
Note how on the 9950X the one million package assets rows are parsed in just 72
ms for Sep_MT (multi-threaded Sep) compared to 119 ms on the 5950X. Or 8 GB/s
on 9950X vs 4.9 GB/s on 5950X. ~8 GB/s! 🚀
Similarly, for floats Sep can parse 8 GB/s of floating point CSV data multi-threaded. ~8 GB/s! 🌪
That’s, about 1.5x-1.6x improvement, similarly to the low level benchmarks, going from 5950X to 9950X. That’s significant generational improvements to CPU performance. Kudos to AMD and TSMC.
Package Assets 5950X
| Method | Rows | Mean | Ratio | MB/s | ns/row | Allocated | Alloc Ratio |
|---|---|---|---|---|---|---|---|
| Sep | 1000000 | 432.887 ms | 1.00 | 1348.6 |
432.9 | 260.41 MB | 1.00 |
| Sep_MT | 1000000 | 119.430 ms | 0.28 | 4888.1 |
119.4 | 261.39 MB | 1.00 |
| Sylvan | 1000000 | 559.550 ms | 1.29 | 1043.3 |
559.6 | 260.57 MB | 1.00 |
| ReadLine_ | 1000000 | 573.637 ms | 1.33 | 1017.7 |
573.6 | 1991.05 MB | 7.65 |
| CsvHelper | 1000000 | 1,537.602 ms | 3.55 | 379.7 |
1537.6 | 260.58 MB | 1.00 |
Package Assets 9950X
| Method | Rows | Mean | Ratio | MB/s | ns/row | Allocated | Alloc Ratio |
|---|---|---|---|---|---|---|---|
| Sep | 1000000 | 291.979 ms | 1.00 | 1999.4 |
292.0 | 260.41 MB | 1.00 |
| Sep_MT | 1000000 | 72.213 ms | 0.25 | 8084.1 |
72.2 | 261.63 MB | 1.00 |
| Sylvan | 1000000 | 413.265 ms | 1.42 | 1412.6 |
413.3 | 260.57 MB | 1.00 |
| ReadLine_ | 1000000 | 377.033 ms | 1.29 | 1548.4 |
377.0 | 1991.04 MB | 7.65 |
| CsvHelper | 1000000 | 1,005.323 ms | 3.44 | 580.7 |
1005.3 | 260.58 MB | 1.00 |
Floats 5950X
| Method | Rows | Mean | Ratio | MB/s | ns/row | Allocated | Alloc Ratio |
|---|---|---|---|---|---|---|---|
| Sep | 25000 | 20.297 ms | 1.00 | 1001.1 |
811.9 | 7.97 KB | 1.00 |
| Sep_MT | 25000 | 3.780 ms | 0.19 | 5375.6 |
151.2 | 179.49 KB | 22.51 |
| Sylvan | 25000 | 52.343 ms | 2.58 | 388.2 |
2093.7 | 18.88 KB | 2.37 |
| ReadLine_ | 25000 | 68.698 ms | 3.38 | 295.8 |
2747.9 | 73493.12 KB | 9,215.89 |
| CsvHelper | 25000 | 100.913 ms | 4.97 | 201.4 |
4036.5 | 22061.69 KB | 2,766.49 |
Floats 9950X
| Method | Rows | Mean | Ratio | MB/s | ns/row | Allocated | Alloc Ratio |
|---|---|---|---|---|---|---|---|
| Sep | 25000 | 16.182 ms | 1.00 | 1255.7 |
647.3 | 7.94 KB | 1.00 |
| Sep_MT | 25000 | 2.497 ms | 0.15 | 8136.8 |
99.9 | 179.81 KB | 22.64 |
| Sylvan | 25000 | 38.800 ms | 2.40 | 523.7 |
1552.0 | 18.72 KB | 2.36 |
| ReadLine_ | 25000 | 54.117 ms | 3.34 | 375.5 |
2164.7 | 73493.05 KB | 9,253.27 |
| CsvHelper | 25000 | 71.601 ms | 4.42 | 283.8 |
2864.1 | 22061.55 KB | 2,777.70 |
🌟 Summary Highlights
AI generated summary highlights 😁
- 🚀 Blazing Fast Parsing: Sep 0.10.0 achieves an incredible 21 GB/s CSV parsing speed on AMD 9950X, a ~3x improvement since its first release in 2023!
- 🖥 Hardware Boost: Upgrading from AMD 5950X (Zen 3) to AMD 9950X (Zen 5) delivers a ~1.6x performance gain, thanks to AVX-512 support and higher clock speeds.
- 🧠 Smarter Parsers: The new AVX-512-to-256 parser circumvents mask register inefficiencies, outperforming AVX2 and older AVX-512 parsers, achieving ~21 GB/s!
- 📊 Cross-Platform Excellence: The
Vector256based cross-platform parser is now on par with AVX2, ensuring top-tier performance across platforms. - 🔬 Deep Dive: Explored .NET 9.0 JIT optimizations, SIMD assembly, and parser design for CSV parsing.
- 🏆 Multi-Threaded Power: Sep parses 1 million rows in just 72 ms on the 9950X, achieving 8 GB/s for real-world CSV workloads.
- 🔧 Continuous Improvement: Incremental optimizations and hardware advancements have propelled Sep to new heights in just under 2 years.
🎉 Sep is a testament to the power of software and hardware working together to push the boundaries of performance!
That’s all!